사실 서버 사이드 자바스크립트는 예전에 생겼다가 사라진 적이 있다. 넷스케프에서 개발했던 웹 애플리케이션 서버인 Netscape Enterprise Server를 이용하면 서버 사이드 자바스크립트로 웹 애플리케이션을 개발할 수 있었다. 하지만 넷스케이프의 쇠퇴와 함께 서버 사이드 자바스크립트 기술도 사라졌다.
그러다 JS자체의 인기가 높아짐에 따라 서버 사이드 자바스크립트도 인기를 얻었고 Node.js가 등장하게 된다. Node.js는 구글에서 발표한 JS 엔진인 V8과 비동기 네트워크 처리를 강점으로 확장성 높은 웹 애플리케이션을 만들 수 있다.
CommonJS
클라이언트 사이드 자바스크립트는 DOM이라는 사실상의 표준 확장 API가 존재한다. 하지만 서버 사이드 자바스크립트는 그런 것이 존재하지 않는다. 그때문에 많은 서버 사이드 자바스크립트는 독자적으로 구현한 API를 가지고 있다. 이런 현상은 개발자와 라이브러리에 부담이 된다. 이를 해결하기 위해 CommonJS라는 표준 API를 제정하려는 욺직임이 나타났다. CommonJS는 API규격을 정하기만 하고 CommonJS에 준거한 각 구현이 규격에 따른 API구현을 제공한다.
CommonJS와 연동하는 형태로 JSGI라는 규격이 존재한다. JSCI는 웹 애플리케이션용 API이다. 자바와 비교하면 서블릿 API에 해당하는 API이다.
하지만 CommonJS의 규격화는 그다지 순조롭지 않다. CommonJS는 오직 모듈 API의 규격만 순조롭게 진행되고 있고 나머지 API는 규격, 구현이 잘 진행되고 있지 않다. 또 한 서버 사이드 자바스크립트 중에서 현재 가장 인기가 높은 Node.js는 원래 비동기 API를 축으로 하고 있지만 CommonJS는 동기 API를 축으로 하고 있다.
따라서 현재 서버 사이드 자바스크립트의 표준 API는 인기가 있는 구현이나 Jquery등의 클라이이언트 사이드로부터의 유입이 사실상의 표준 API가 되고 이를 CommonJS가 받아들이는 형태가 될것이다.
모듈 기능
모듈이 필요한 이유
클라이언트 사이드 자바스크립트에서 HTML안의 script 태그로 여러 JS 파일을 읽어들인다고 하자. 이때 script 태그를 이용한 JS파일 읽기는 파일을 단순히 연결하고 있는 인클루드 구조이다. 그때문에 자칫하면 전역 네임스페이스 오염에 의해 충돌이 발생한다.
서버 사이드 자바스크립트에서도 인클루드 구조로 여러 개의 소스 파일을 연결할 수 있다. 하지만 인클루드에 의한 파일 연결은 파일 수가 늘어날 수록 관리가 어렵다. CommonJS의 모듈 규격은 이 문제를 해결한다. CommonJS 모듈은 기본적으로 전역 네임스페이스를 오염시키지 않는다. 두 개의 소스 파일을 합칠 때 한 쪽 파일의 변수명이나 함수명을 export하지 않는 한 다른 파일에서 보이지 않는다.
모듈로 읽히는 쪽은 처음부터 exports와 module이라는 두 개의 객체가 존재한다. 모든 파일이 모듈로 읽히기 때문에 모든 파일에는 exports와 module 객체가 암묵적으로 존재한다. 이 객체들의 프로퍼티를 설정하는 것이 그 파일을 모듈로 사용하게 만드는 데 필요한 작업이다.
모듈 export
|
1
2
3
4
5
|
function sum (a, b) {
return Number(a) + Number(b);
}
exports.sum = sum;
|
cs |
module객체에는 id와 url이라는 read-only property가 존재한다. 이들은 모듈을 식별하기 위한 모듈명에 해당하는 값 을 가진다. 파일단위의 모듈의 모듈명은 파일명이다.
모듈을 사용하는 코드
모듈을 사용하기 위하서는 require 함수를 사용한다.
|
1
2
|
const calc = reuqire('calc');
console.log(calc.sum(1, 2));
|
cs |
require 함수에 전달하는 모듈명에 대응하는 파일을 찾는 방식은 구현에 의존한다.
모듈의 대응
require 함수에는 main과 path라는 두 개의 프로퍼티가 존재한다. main 프로퍼티는 다음과 같이 module 객체와의 동 일성을 판정해 그 파일이 직접 실행됬는지 아니면 모듈로 읽었는지를 판별한다.
|
1
2
3
4
5
|
if (require.main === module) { // 파일을 직접 읽었으면 참
...
} else { // 모듈로 읽었으면
...
}
|
cs |
require.path property는 모듈을 찾는 파일 경로의 배열이다. 다음과 같은 코드를 활용해 실행할 때 모듈 파일을 찾는 경로를 변경할 수 있지만 권장하지 않는다.
|
1
|
require.paths.unshift(__dirname + '/path');
|
cs |
Node.js
Node.js는 다음과 같은 특징을 갖는다.
1. 자바스크립트 엔진은 V8
2. 비동기 처리인 범용 이벤트 루프를 제공하는 엔진
3. 인터렉티브 셸 기능을 제공하는 명령행 도구 제공
4. 패키지 시스템에 의한 확장성
서버 사이드 기술이라 하면 통상적으로 웹 애플리케이션 레이어를 가리키지만 Node.js는 일반적인 웹 애플리케이션 서버보다 낮은 레이어의 소프트웨어이다.
다른 서버 사이드 자바스크립느는 아파치 같은 기존 웹 서버나 톰캣 같은 기존 자바 서블릿 엔진에서 동작하는 것이 일반적이다. 반면 Node.js로 웹 애플리케이션을 만드는 경우 Node.js로 HTTP 서버의 레이러로부터 웹 애플리케이션 서버의 레이어 까지 만들 수 있다. 따라서 Node.js의 위치를 펄 같은 스크립트 언어와 같은 레이어의 소프트웨어로 간주하는 것이 적절하다. 기반이 되는 JS 엔진인 V8에 라이브러리 층을 올리고, 거기에 명령행 도구인 node를 조합해 펄과 동등한 존재로 자리매김한다.
비동기 처리와 논블로킹 처리
블로킹과 논블로킹이라는 용어는 어떤 처리의 호출, 일반적으로는 함수 호출에 대한 표현이다.
블로킹 함수는 함수 안에서 대시 상태가 될 수 있는 함수다.
논블로킹 함수는 대기 상태다 되지 않는 함수이다. 대기 상태는 어떤 리소스를 구하기 위해 기다리면서 발생한다. 실행 단계에서 보면 I/O 대기나 lock 대기가 일반적이다.
동기 처리와 비동기 처리는 표현하는 대상에 따라 다르지만 Node.js에서는 I/O 처리를 표현하는 것이라 생각하면 된다. 동기 I/O 처리는 읽기 또는 쓰기 처리를 시작하면 완료될 때까지 아무것도 하지 않는다. 대부분 일기 처리에서 동기 I/O로 인한 대기 상태가 발생한다. 쓰기 처리의 경우에는 버퍼 메모리에 쓰는 것을 완료로 간주하고 성능을 올린다. 버퍼가 다 찼을 때 쓰기를 기다리게 할 것인지는 해당 함수가 블로킹이냐 논블로킹이냐에 따라 다르다.
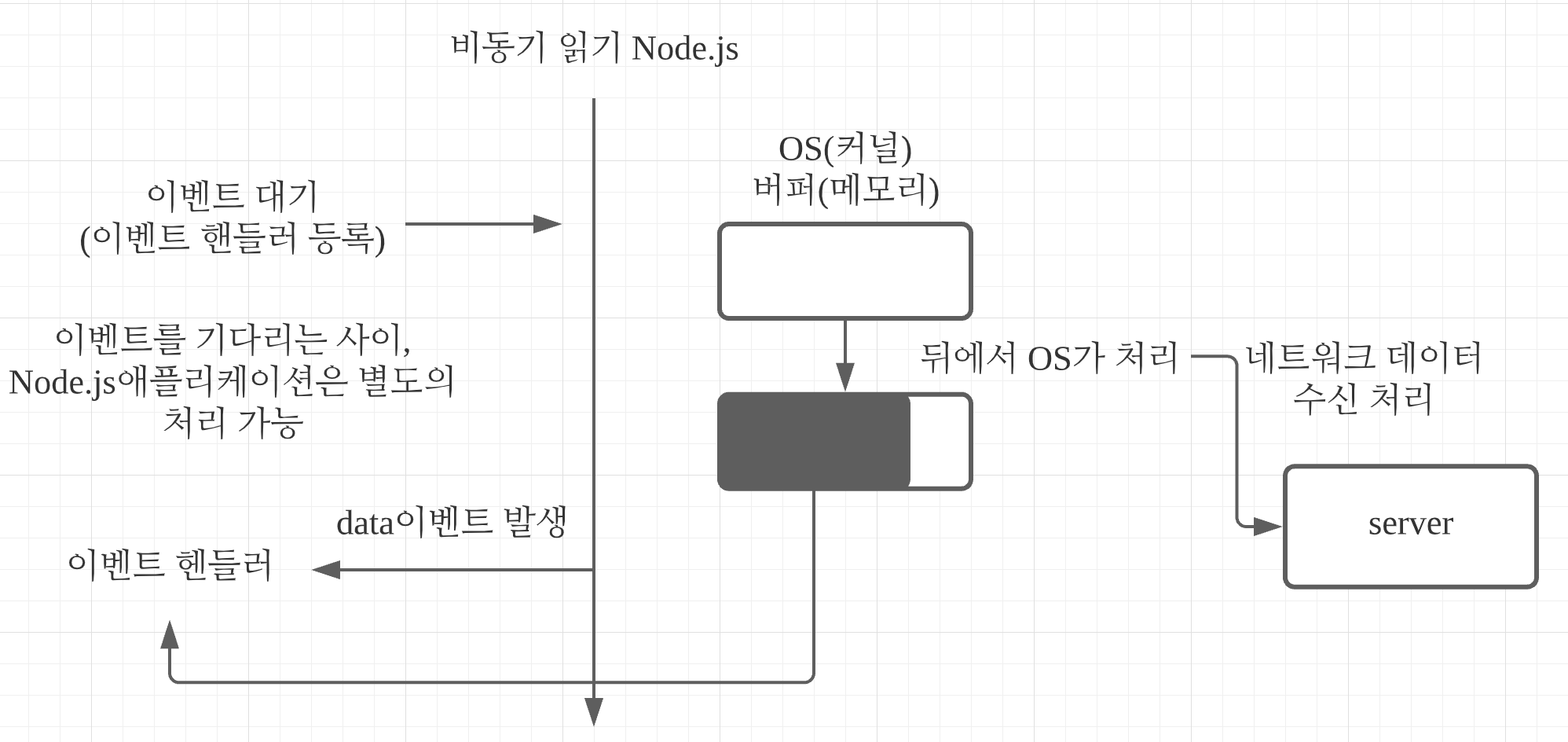
비동기 I/O 처리는 읽기 처리를 뒤(OS)에서 처리한다. 좁은 의미의 비동기 읽기 처리는 읽기가 완료된 타이밍에 이벤트를 발생시킨다. 이 시점에는 읽기 데이터가 메모리에 이미 읽힌 상태이다. 넓은 의미의 비동기 읽기 처리는 읽기 가능한 타이밍에 이벤트가 발생하고, 그 이벤트에 대응하는 도중 애플리케이션이 읽기 처리를 한다.
비동기 쓰기 처리는 써야 할 데이터를 버퍼가 될 메모리에 준비해 두면, 쓰기가 완료된 시점에 이벤트가 발생한다. 이 이벤트는 암묵적으로 메모리 버퍼에 새로운 데이터를 쓸 공간이 생기는 것을 의미한다. 넓은 의미의 비동기 쓰기 처리는 실제로 쓰기가 가능한 타이밍에 이벤트를 발생시키고, 이벤트에 대응해서 처리하는 과정에서 쓰기를 처리한다.
네트워크의 I/O작업은 대기 상태가 될 수 있는 작업이다. 그래서 네트워크 처리를 I/O로 하는 함수는 결과적으로 블로킹 함수가 된다. 네트워크 동기 I/O처리는 블로킹 함수와 같은 의미이다.
비동기 I/O 처리는 조금 더 의미가 다양하고 구현 방법에도 차이가 있다. 보통 비동기인 데이터 읽기 함수는 논블로킹이지만, 이론상으로는 데이터의 읽기가 가능한지 확인하는 함수와 블로킹하는 읽고 쓰기 함수의 조합으로도 구현할 수 있다. 그래서 비동기 I/O처리에 논블로킹 함수가 필수적인 요소가 아니다. 하지만 사실상 비동기 I/O처리와 논블로킹 함수는 같다.
네트워크 처리처럼 본질적으로 대기 상태가 발생할 수 있는 경우, 병렬 처리를 구현하기 위해 다중 스레드나 비동기 처리 중 한 쪽의 구조가 필요하다.
Node.js의 비동기 처리의 동작 방식
구현을 보면 비동기 처리의 쓰기와 읽기는 일반적으로 메모리를 읽고 쓰는 용도의 버퍼로 사용하기 떄문에 비대칭적이다. 메모리를 읽고 쓰는 것은 블로킹하지 않는다는 것을 전제로 한다.
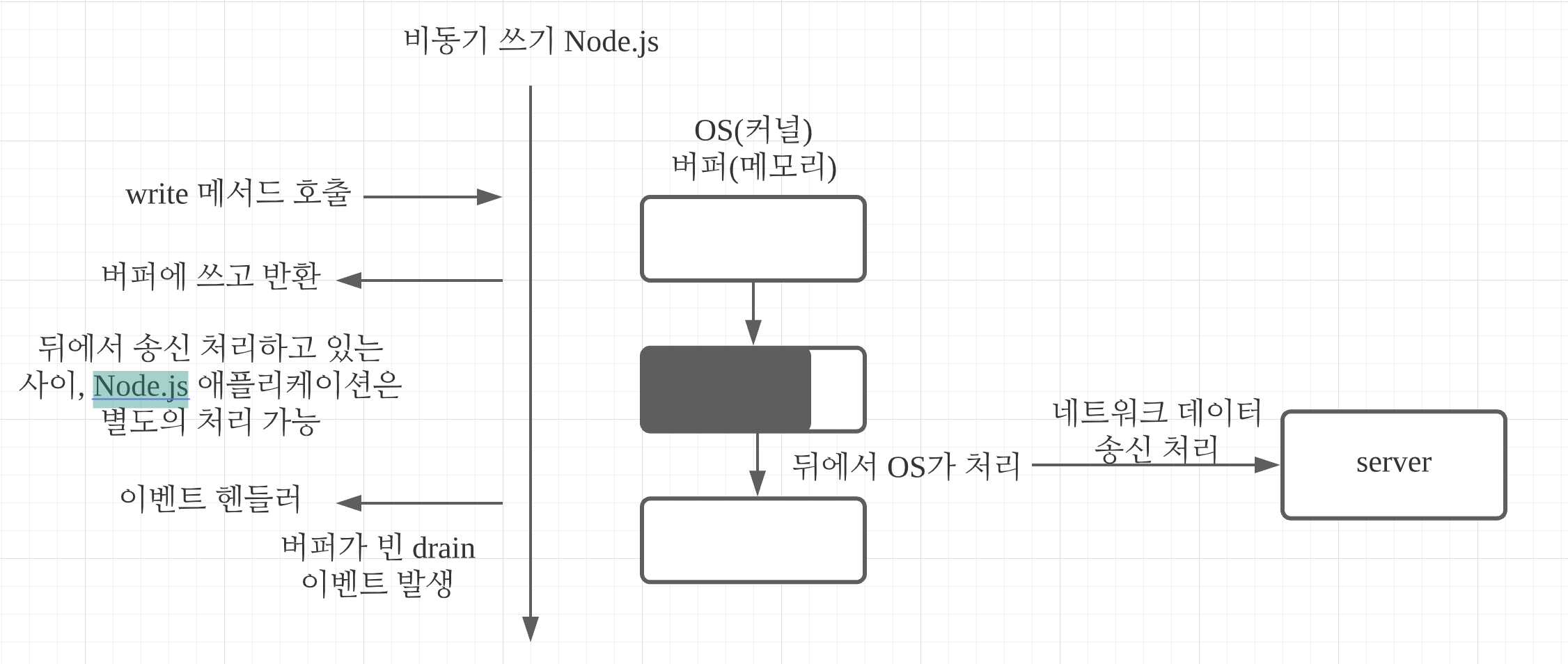
Node.js의 비동기 쓰기 처리는 메서드의 호출로 이뤄진다. 메서드를 호출하면 기본적으로 논블로킹으로 즉시 반환한다. 백그라운드에서 비동기로 수행한다.
쓰기 처리가 끝난 타이밍의 이벤트에 다음 쓰기를 하는 것은 효율적이지 않다. 좋은 쓰기 처리는 완료 타이밍을 긴다맂 않고 쓰기 메서드를 차례로 호출한다. 실제 쓰기 처리의 타이밍을 신경쓰지 않고 버퍼에 쓰면 좋기 때문이다. 하지만 극단적으로 큰 데이터를 사용한다면 버퍼의 사이즈가 너무 커져서 메모리를 압박할 위험이 있다. 이런 경우에는 버퍼가 빈 타이밍의 이벤트를 기다려 다음 쓰기를 하는 식의 제어가 필요하다.
Node.js의 비동기 읽기 처리에 대응하는 함수나 메서드가 존재하지 않는다. 읽기는 이벤트에 대한 콜백으로 이루어진다. 이벤트명은 data가 일반적이다. 뒤에서 읽기 처리가 완료되고 데이터가 메모리에 있는 상태로 콜백 함수가 호출된다. 콜백 함수의 인자로 읽기 데이터를 받는다. 읽기 처리가 계속되는 경우 콜백 함수가 차례로 호출된다. 여기서 일반 함수와의 차이가 존재한다. 일반적인 함수 호출에서는 함수에 넘기는 인자를 입력해 반환값이 출역되지만 콜백 함수를 사용하는 비동기 처리에서는 콜백 함수의 인자 형태로 출력을 얻는다.
모듈
Node.js 모듈의 기본적인 구조는 CommonJS의 모듈 규격을 따른다. 모듈의 기본적인 사용법은 CommonJS와 같다. require의 인자에 모듈명을 지정하는 방법은 다음과 같다.
| 명칭 | 예시 |
| 상태 경로 | ../foo |
| 절대 경로 | /foor |
| 이름 | foo 또는 foo.js |
모듈명과 파일명의 대응은 다음과 같은 순서로 매치되고 최초로 발견된 파일을 로드한다.
1. 완전히 일치하는 파일명
2. 확장자 js를 부여한 파일명
3. 확장자 node를 부여한 파일명(바이너리 모율로 로드)
상대 경로를 지정하는 require함수는 상대경로, 절대경로외의 이름의 파임을 다음과 같은 순서로 찾는다.
1. 코어 모듈에 이름이 일치하면 코더 모듈을 로드
2. 현재 디렉터리의 node_modules 디렉터리 밑
3. 현재 디렉터리에서 상위 디렉터리를 향해 node_module 디렉터리를 검색
4. NODE_PATH 환경변수에서 지정한 디렉터리
5. $HOME/.node_modules/ 디렉터리
6. $HOME/.node_libraries/ 디렉터리
7. {NODE.js 설치 디렉터리}/lib/node/ 디렉터리
모듈 안에서 작성한 코드는 reuqire를 호출할 때 실행된다. require를 여러번 호출해도 단 한번만 실행된다. require의 반환값에 포함된 객체 참조도 항상 동일하다.
npm과 패키지
모듈은 Node.js 자체가 제공하는 프로그램의 분할 제어를 돕는 언어 기능이다. 소스코드를 여러 파일에 나눠서 관리할 수 있는 구조로 더 구체적으로 말하면 네임스페이스를 분리할 수 있는 언어 기능이다.
패키지는 배포를 위한 구조다. 패키지는 모듈의 집합으로 정의된다.