동작 파라미터화를 이용하면 더 유연하고 재사용할 수 있는 코드를 만들 수 있다. 익명 클래스로 다양한 동작을 구현할 수 있지만 코드가 깔끔하지 않다. 깔끔하지 않다는 것은 실전에 적용하는 것을 막는 요소다. 그에 반해 람다는 익명 클래스처럼 이름이 없는 함수면서 메서드를 인수로 전달할 수 있고 코드 역시 깔끔하다.
이번 장에서는 람다에 대해 다룬다.
람다란 무엇인가?
람다 표현식은 메서드로 전달할 수 있는 익명 함수를 단순화한 것이다. 람다 표현식에는 이름은 없지만, 파라미터 리스트, 바디, 반환 형식, 예외 리스트를 가질 수 있다. 람다 특징은 다음과 같다.
1. 익명: 람다는 이름이 없다. 따라서 구현해야 할 코드에 대한 걱정이 준다.
2. 함수: 람다는 메서드처럼 특정 클래스에 종속되지 않기 때문에 함수다. 하지만 메서드처럼 파라미터 리스트, 바디,
반환 형식, 예외 리스트를 포함한다.
3. 전달: 람다 표현식을 메서드 인수로 전달하거나 변수로 저장할 수 있다.
4. 간결성: 익명 클래스처럼 많은 코드를 구현할 필요가 없다.
위의 특징을 다음 예시에서 더 명시적으로 확인할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 익명 클래스 사용
Comparator<Apple> byWeight = new Comparator<Apple>() {
public int compare(Apple a1, Apple a2) {
return a1.getWeight().compareTo(a2.getWeigth());
}
};
// 람다 사용
// 람다를 사용해 compare 메서드의 바디를 직접 전달하는 것처럼 코드를
// 전달했다.
Comparator<Apple> byWeight =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
|
cs |
람다 구조는 다음과 같은 3개의 요소로 이뤄진다.
1. 파라미터 리스트: 파라미터 목록
2. 화살표: 파라미터 리스트와 람다 바디를 구분한다
3. 람다 바디: 람다의 반환값에 해당하는 표현식이다.
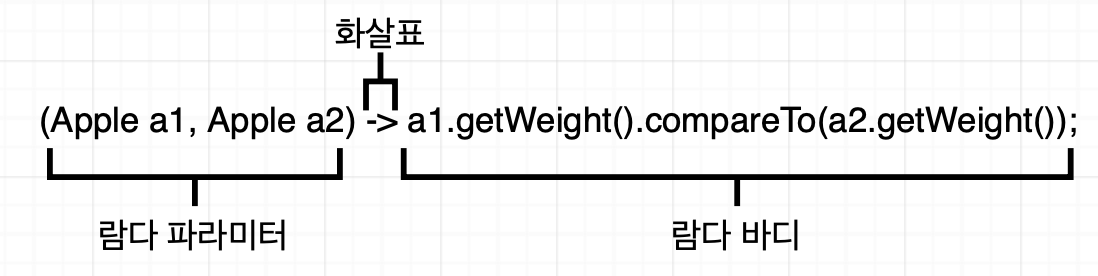
람다 표현식은 "{}"을 사용할 수 있다. "{}"를 사용해 코드를 감싸고 반환값이 있다면 명시적으로 return을 활용해 반환해야 하고 사용하지 않는다면 그 코드 한 줄 자체로 반환값이 된다.
|
1
2
3
4
5
|
() -> "hello" // hello 반환
() -> {
return "hello"; // hello 반환
}
|
cs |
어디에, 어떻게 람다를 사용할까?
람다 표현식은 함수형 인터페이스라는 문맥에서 사용할 수 있다.
함수형 인터페이스
함수형 인터페이스는 오직 하나의 추상 메서드를 지정할 수 있다. 단, 여러 개의 디폴트 매서드는 가질 수 있다. 자바 API에서 Comparator나 Runnable이 함수형 인터페이스다.
|
1
2
3
4
5
6
7
8
9
10
|
// java.util.Comparator
public interface Comparator<T> {
int compare(T o1, T o2);
}
// java.lang.Runnable
public interface Runnable {
void run();
}
|
cs |
함수형 인터페이스를 사용하면 람다 표현식으로 함수형 인터페이스의 추상 메서드 구현을 직접 전달할 수 있어서 전체 표현식을 함수형 인터페이스의 인스턴스(함수형 인터페이스를 구현한 클래스의 인스턴스)로 취급할 수 있다.
함수 디스크립터
함수형 인터페이스의 추상 메서드 시그니처(signature)는 람다 표현식의 시그니처를 가리킨다. 람다 표현식의 시그니처를 서술하는 메서드를 함수 디스크립터(function descriptor)라 한다. 예를 들어 Runnable 인터페이스의 유일한 추상 메서드 run은 인수와 반환값이 없기 때문에 Runnable 인터페이스는 인수와 반환값이 없는 시그니처로 생각할 수 있다.
시그니처는 컴파일러가 함수를 구분하기 위한 구성요소를 말한다. 시그니처를 구성하는 요소는 강타입일 경우 아래의 요소를 포함한다.
1. 함수의 이름
2. 매개변수의 개수
3. 매개변수의 자료형
4. 반환하는 값의 자료형
@FunctionalInterface 어노테이션은 함수형 인터페이스를 가리키는 어노테이션이다. @FunctionalInterface로 인터페이스를 선언했지만 함수형 인터페이스가 아니라면 컴파일러가 에러를 발생시킨다.
람다 활용: 실행 어라운드 패턴
람다와 동작 파라미터화로 유연하고 간결한 코드를 구현하는 데 도움을 주는 예시를 살펴보자. 자원처리(DB에 파일 처리 같은)에 사용되는 순환 패턴(recurrent pattern)은 자원을 열고, 처리하고, 자원을 닫는 순서로 이뤄진다. 설정(setup)과 정리(cleanup)과정은 대부분 비슷하다. 이렇게 중복되는 준비 코드와 정리 코드가 실제 자원을 처리하는 코드를 둘러싼 형태가 실행 어라운드 패턴(execute around pattern)이다.

아래 예시는 파일에서 한 행을 읽는 코드이다.
|
1
2
3
4
5
6
7
|
public String processFile() throws IOException {
try (BufferedReader br =
new BufferedReader(new FileReader("data.txt"))) {
return br.readLine();
}
}
|
cs |
위 코드는 오직 한 번에 한 줄만 읽는 기능만 하기 때문에 유연하지 않다. 따라서 람다와 함수형 인터페이스를 통한 동작 파라피터화로 다음과 같이 유연성을 확보할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
@FunctionanlInterface
public interface BufferedReaderProcessor {
String process(BufferedReader b) throw IOException;
}
public String processFile(BufferedReaderProcessor p) throws IOException {
try (BufferedReader br =
new BufferedReader(new FileReader("data.txt"))) {
return p.process(br)
}
}
String oneLine = processFile((BufferedReader br) -> br.readLine());
String twoLine = processFile((BufferedReader br) -> br.readLine() + br.readLine());
|
cs |
함수형 인터페이스 사용
자바 8은 java.util.function 패키지로 여러 가지 새로운 함수형 인터페이스를 제공한다. 이런 함수형 인터페이스들의 기본적인 사용법은 아래 링크를 참고하자.
https://iskull-dev.tistory.com/205?category=978162
함수형 인터페이스와 람다 표현식
함수형 인터페이스와 람다 표현식은 자바에서 함수형 프로그래밍을 할 수 있게 해주는 초석이다. 하지만 이들은 반드시 함수형 프로그래밍 만을 위해서 사용하라는 법은 없다. 함수형 인터
iskull-dev.tistory.com
자바 8에서 추가된 함수형 인터페이스와 그게 상응하는 함수 디스크립터는 다음과 같다.
| 함수형 인터페이스 | 함수 디스크립터 |
| Predicate<T> | T -> boolean |
| Consumer<T> | T -> void |
| Function<T, R> | T -> R |
| Supplier<T> | () -> T |
| UnaryOperator<T> | T -> T |
| BinaryOperator<T> | (T, T) -> T |
| BiPredicate<L, R> | (T, U) -> boolean |
| BiConsumer<T, U> | (T, U) -> void |
| BiFunction(T, U, R) | (T, U) -> R |
기본형 특화
제네릭 파라미터에는 참조형만 사용할 수 있다. 따라서 기본형을 입출력해야 하는 상황에서 제네릭이 사용된다면 오토박싱으로 인해 래퍼 클래스가 힙에 저장된다. 박싱한 값은 메모리를 더 소비하고 기본형을 가져올 때도 메모리를 탐색하는 과정이 필요하다.
자바 8에서는 기본형을 입출력하는 상황에서 오토박싱을 피할 수 있는 함수형 인터페이스를 제공한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 일반 Predicate
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
}
// int primitive type용 Predicate
@FunctionalInterface
public interface IntPredicate {
boolean test(int t);
}
IntPredicate evenNumbers = (int i ) -> i % 2 == 0;
evenNumbers.test(1000); // true
|
cs |
예외, 람다, 함수형 인터페이스의 관계
함수형 인터페이스는 확인된 예외를 던지는 동작을 허용하지 않는다. 따라서 예외를 던지는 람다 표현식을 만들기 위해서는 확인된 예외를 선언하는 함수형 인터페이스를 직접 정의하거나 람다를 try-catch 블록으로 감싸야 한다.
예를 들어 IOException을 명시적으로 선언하는 함수형 인터페이스 BufferedReaderProcessor의 확인된 예외는 다음과 같이 잡을 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@FunctionalInterface
public interface BufferedReaderProcessor {
String process(BufferedReader b) throws IOException;
}
Function<BufferedReader, String> f = (BufferedReader b) -> {
try {
return b.readLine();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
|
cs |
형식 검사, 형식 추론, 제약
람다 표현식을 사용해 함수형 인터페이스의 인스턴스를 만들 수 있지만 람다 표현식에는 어떤 함수형 인터페이스를 구현하는지의 정보가 없다.
형식 검사
람다가 사용되는 콘텍스트(context, 람다가 전달될 메서드 파라미터, 람다가 할당되는 변수 등)를 이용해 기대되는 람다의 형식인 대상 형식(target type)을 추론할 수 있다. 아래의 그림은 형식 확인 과정을 도식화 한거다.
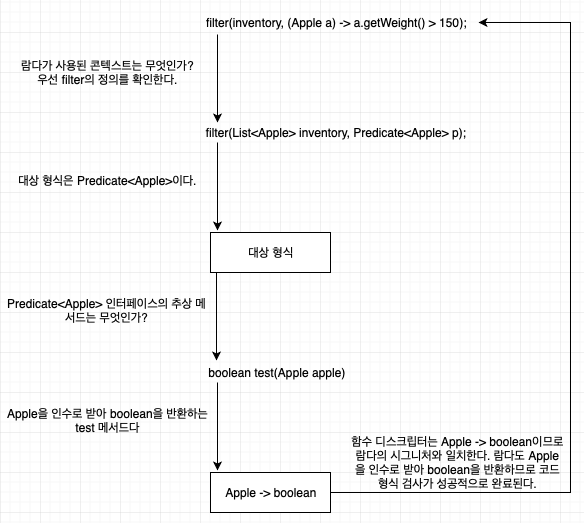
같은 람다, 다른 함수형 인터페이스
대상 형식이라는 특징 때문에 같은 람다 표현식이더라도 호환된느 추상 메서드를 가진 다른 함수형 인터페이스로 사용될 수 있다.
다이아몬드 연산자.
자바 7에서는 "<>"로 콘텍스트에 따른 제네릭 형식을 추론할 수 있다. 주어진 인스턴스 표현식의 형식 인수는 콘텍스트에 의해 추론된다.
|
1
|
List<String> listOfStrings = new ArrayList<>();
|
cs |
특별한 void 호환 규칙
람다의 바디에 일반 표현식이 있으면 void를 반환하는 함수 디스크립터와 호환된다. 예를 들어 List의 add메서드는 boolean을 반환하지만 Consumer와 호환된다.
|
1
|
Consumer<String> b = s -> list.add(s);
|
cs |
형식 추론
위 형식 검사를 보면 자바 컴파일러는 람다 표현식이 사용된 대상 형식을 이용해 람다 표현식과 관련된 함수형 인터페이스를 추론하고 함수 디스크립터를 알 수 있어서 람다의 시그니처를 추론할 수 있다. 따라서 컴파일러는 람다 표현식의 파라미터 형식에 접근할 수 있어서 파라미터 형식을 생략할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
|
// 람다에 형식 추론 대상 파라미터가 하나라면 파라미터명을 감싸는 괄호
// 생략 가능
List<Apple> GreenApples =
filter(inventory, apple -> Green.equals(apple.getColor()));
Comparator<Apple> c =
filter(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
// 위 Comparator와 같은 동작을 한다.
Comparator<Apple> c =
filter(a1, a2) -> a1.getWeight().compareTo(a2.getWeight());
|
cs |
지역 변수 사용
람다 표현식에서는 자유 변수(free variable, 파라미터로 넘겨야 하는 변수가 아닌 외부에서 정의된 변수)를 활용할 수 있다. 이를 람다 캡쳐링(capturing lambda)라 한다.
람다가 지역 변수를 캡쳐링 하려면 해당 지역 변수는 final 또는 effective final로 선언되 있어야 한다. 이런 제약이 생긴 이유는 인스턴스 변수는 힙에 할당되지만 지역 변수는 스택에 할당되기 때문이다. 람다에서 지역 변수에 바로 접근하는 것이 허용된다 가정해 보자. 람다가 스레드에서 실행된다면 변수를 할당한 스레드가 사라져서 변수 할당이 해제되었음에도 람다를 실행하는 스레드에서는 해당 변수에 접근하려 할 수 있다. 따라서 지역 변수의 복사본을 만들어 제공하기 때문에 복사본의 값이 바뀌지 않아야 한다.
클로저
클로저는 함수의 비지역 변수를 자유롭게 참조할 수 있는 함수의 인스턴스이다. 람다와 익명 함수는 클로저의 정의에서 자신의 외부 변수에 접근할 수 있다는 조건을 만족한다. 하지만 자신이 정의된 메서드의 지역 변수의 값은 바꿀 수 없으므로 클로저 정의에 부합하지 않는다.
메서드 참조
메서드 참조는 특정 메서드만을 호출하는 람다의 축약형이라 생각할 수 있다. 메서드 참조를 이용하면 기존 메서드 구현으로 람다 표현식을 만들 수 있는데 여기서 명시적으로 메서드명을 참조해 가독성을 높일 수 있다.
|
1
2
3
4
5
6
|
inventory.sort((Apple a1, Apple a2) ->
a1.getWeight().compareTo(a2.getWeight()));
// 위 코드와 같은 동작을 한다
// 메서드 참조 사용
inventory.sort(comparing(Apple::getWeight));
|
cs |
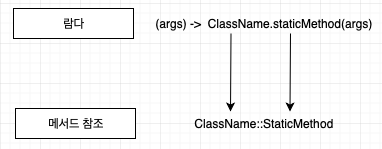
메서드 참조는 세 가지 유형이 있으며 다음과 같이 변환이 가능하다.
1. 정적 메서드 참조
2. 다양한 형식의 인스턴스 메서드 참조

3. 기존 객체의 인스턴스 메서드 참조
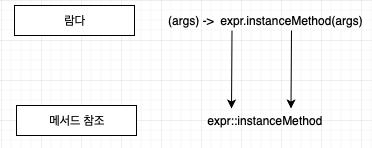
컴파일러는 람다 표현식의 형식을 검사하는 과정과 유사하게 메서드 참조가 주어진 함수형 인터페이스와 호환하는지 확인한다. 즉, 메서드 참조는 콘텍스트의 형식과 일치해야 한다.
생성자 참조
클래스 명과 new 키워드를 사용해 기존 생성자의 참조를 만들 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// 디폴트 생성자는 Supplier 인터페이스와 같은 시그니처를 갖는다.
// Supplier<Apple> c2 = () -> new Apple();
Supplier<Apple> c1 = Apple::new;
// Supplier의 get메서드 호출로 새로운 Apple 객체 생성
Apple a1 = c1.get();
// 두 인수를 갖는 생성자는 BiFunction 인터페이스와 같은 시그니처를
// 갖는다. ex) Apple(String color, Integer weight)
// BiFunction<Color, Integer, Apple> c2 = (color, weight) ->
// new Apple(color, weight);
BiFunction<Color, Integer, Apple> c2 = Apple::new;
// BiFunction apply 메서드에 color와 weight을 제공해
// 새로운 Apple 객체 생성
Apple a2 = c2.apply(GREEN, 110);
|
cs |
람다 표현식을 조합할 수 있는 유용한 메서드
자바 8의 함수형 인터페이스들은 다양한 디폴트 메서드들을 지원한다. 이 디폴트 메서드들을 활용해 람다 표현식을 조합하고 복잡한 람다 표현식을 만들 수 있다.
Comparator
Comparator는 Comparable 키를 추출해 Comparator 객체로 만드는 Function 함수를 인수로 받는 comparing 메서드를 제공한다. 따라서 다음과 같이 정렬 코드를 간소화 할 수 있다.
|
1
2
3
4
5
6
7
|
inventory.sort((Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight()));
// 아래와 같이 줄일 수 있다.
// comparing(Apple::getWeight)는
// Comparator.comparing((Apple a) -> a.getWeight())와 같다.
import static java.util.Comparator.comparing;
inventory.sort(comparing(Apple::getWeight));
|
cs |
이 방식과 내림차순 정렬을 하는 reverse 디폴트 메서드, 정렬 조건이 같을 때 사용하는 두 번째 비교 조건을 설정할 수 있는 thenComparing 메서드를 조합하면 다음과 같은 코드를 작성할 수 있다.
|
1
2
3
4
5
6
|
// 무게순으로 내림차순 정렬을 한다.
// 무게가 같으면 국가별로 정렬한다.
inventory.sort(comparing(Apple::getWeight))
.reversed()
.thenComparing(Apple::getCountry);
|
cs |
Predicate
negate 메서드는 결과를 반전시킨다. a.and(b)와 같이 사용 가능한 and 메서드는 "a&&b"이다. a.or(b)는 and와 마찬가지로 "a||b"이다. redApple는 빨간 사과를 판별하는 Predicate라 할때, 다음과 같이 사용할 수 있다.
|
1
2
3
4
5
6
7
8
|
// redApple의 결과를 반전한 객체를 만든다.
Predicate<Apple> notRedApple = redApple.negate();
// (빨간색 && 150그램 초과) || 녹색 사과
Predicate<Apple> redAndHeavyAppleOrGreen =
redApple.and(apple -> apple.getWeight() > 150)
.or(apple -> GREEN.equals(a.getColor()));
|
cs |
Function
Function은 Function 인터페이스를 반환하는 andThen, compose 디폴트 메서드를 지원한다.
andThen 메서드는 주어진 함수를 먼저 적용한 결과를 다른 함수의 입력으로 전달하는 함수를 반환한다.
|
1
2
3
4
5
6
7
|
// 함수 f(x)
Function<Integer, Integer> f = x -> x + 1;
// 함수 g(x)
Function<Integer, Integer> g = x -> x * 2;
// 함수 h(x) = f(g(x))
Function<Integer, Integer> = f.andThen(g);
|
cs |
compose 메서드는 인수로 주어진 함수를 먼저 실행한 다음 그 결과를 외부 함수의 인수로 제공한다.
|
1
2
3
4
5
6
7
|
// 함수 f(x)
Function<Integer, Integer> f = x -> x + 1;
// 함수 g(x)
Function<Integer, Integer> g = x -> x * 2;
// 함수 h(x) = g(f(x))
Function<Integer, Integer> = f.compose(g);
|
cs |
출처 - 모던 자바 인 액션.