upsteram, origin
어떤 저장소 A가 있다고 해보자. 이 저장소를 내 깃허브에 fork하고 fork한 저장소를 local에 clone받는다 해보자. 그러면 다음과 같은 관계가 형성된다.
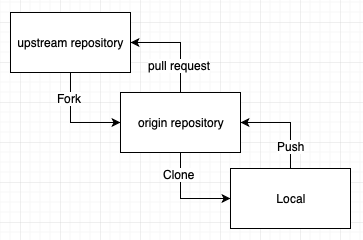
여기서 upstream, downstream은 두 저장소 간의 관계에 따라 정의되는 상대적 개념이다. 위 그림에서 origin repository의 upstream은 upstream repository이다. 하나의 upstream에서 여러 개의 downstream이 생성될 수 있다.
upstream과 origin 차이
통상적으로 내가 다른 사람의 저장소를 포크해왔을 때 upstream은 일반적으로 다른 사람의 저장소를 의미한다.
origin은 내가 포크한 내 깃허브에 있는 저장소를 의미한다. 저장소가 클론될 때 리모트는 origin이라 불린다.
upstrema 설정하기
깃허브에서 빈 저장소를 만들면 다음과 같은 커멘드들을 볼 수 있다.
|
1
2
3
4
5
6
7
|
git init
git add README.md
git commit -m "first comit"
git branch -M main
git remote add origin https://github.com/example/a.git
git push -u origin main
|
cs |
여기서 "git remote add origin https://github.com/example/a.git"은 원격 저장소인 a.git을 origin이라는 별칭으로 이름을 부여해 관리를 하겠다는 의미다.
"git push -u origin main"은 origin 저장소의 main branch로 push하겠다는 의미다. 여기서 -u는 --set-upstream의 약자로 upstream과 downstream 관계를 설정해 주기 위해서 사용된다.
git clone을 사용할 경우 이미 origin을 알고 있기 때문에 upstream, downstream 관계가 자동으로 설정된다.
add, commit, push
git init을 하면 해당 디렉토리는 소스코드를 작접하는 working directory이고 로컬 저장소는 .git 안에 생성된다.

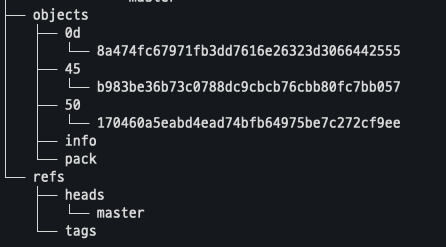
.git의 내부 구조는 다음과 같다.
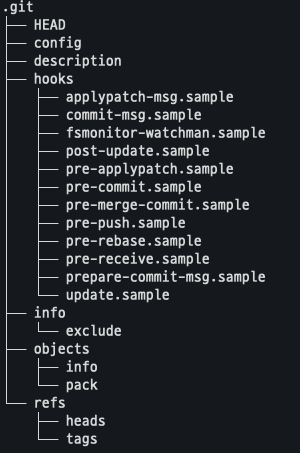
git은 여러 객체들을 가지고 있고 이들을 활용한다. blob, commit, tree, tag는 객체지만 branch는 객체가 아닌 commit 객체들에 대한 참조다.
bolb - 소스코드 파일들을 관리하는 객체
commit - 저장 단위, tree + blob + 메타정보
tree - Blob를 묶어서 관리(디렉토리 구조와 유사하다)
tag - 커밋에 대한 참조지만 설명이 추가되는 객체
commit
커밋은 작업 디렉토리의 스냅샷, 세이브 포인트다. 커밋은 스테이지의 내용으로 tree 객체를 생성하고, commit 객체는 tree 객체를 포함한다.
commit 객체에는 다음과 같은 것들이 저장된다.
1. 최상위 트리 객체의 참조 (tree의 해시값)
2. 부모 커밋에 대한 참조(부모 커밋의 해시값)
3. 작성자와 커미터의 이름, 이메일 주소
4. 커밋 메시지
git add와 git commit을 했을 때 생성되는 객체가 다르다.
git add 를 하면 git이 해당 파일을 인식한다. 따라서 git add를 한 상태에서 .git 내부를 보면 index와 objects 내에 객체가 하나 추가되게 된다.
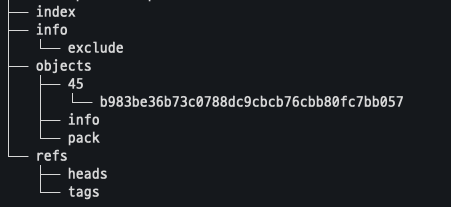
이 상태에서 git commit을 하면 objects에 두 개의 객체가 생성되게 된다.
즉, git add를 하면 blob 객체가 생성되고 git commit을 하면 tree 객체와 commit 객체가 생성된다. 따라서 두 개의 파일을 add 하고 commit했다면 해당 commit을 다음과 같은 객체를 갖는다.
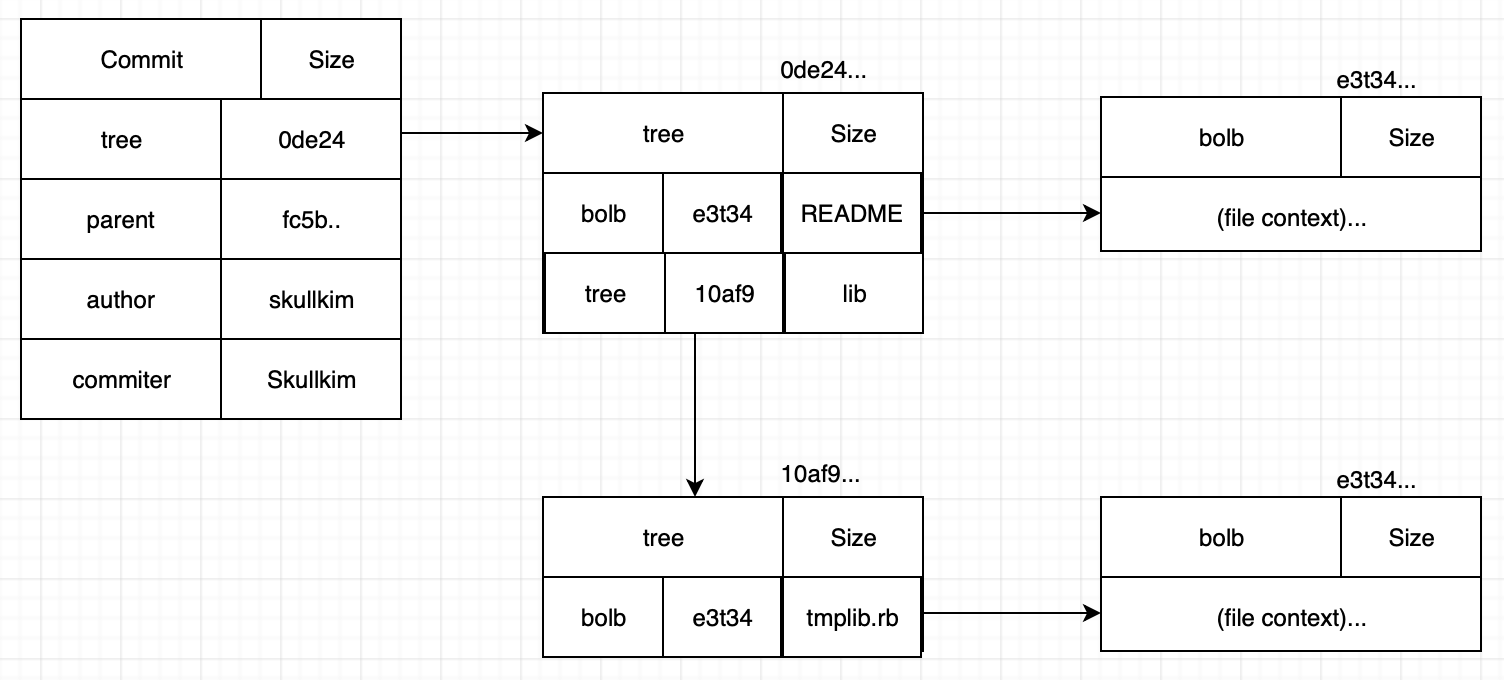
여기서 git add와 git commit을 나눈 이유는 git은 공간 효율을 위해 변경사항만 저장하는 것이 아닌 모든 파일을 통채로 저장하고 각 파일을 객체로 관리하기 때문이다. 물론 변경사항만 저장한다면 공간적으로는 이점이 있지만 파일이 많아지고 커밋을 되돌린다면 버전들의 변경 사항을 추적하기 위해 상당한 연산을 수행해야 하므로 연산 비용을 낮추기 위해 파일을 통채로 저장한다.
이런 상황에서 여러 브랜치에, 여러 커밋에 같은 내용을 담고 있는 파일들을 서로 다른 객체로 만들어 관리한다면 관리해야 하는 파일들의 용량이 기하급수적으로 늘어난다. 따라서 이들을 참조하기 위한 tree 객체를 만들고 tree 객체를 commit 객체가 관리한다. 이런 구조를 만들기 위해서 파일을 관리하기 위함과 커밋을 관리하는 행위를 구분지어야 한다. 이를 위해 add 와 commit을 나누었다.