Mysql 서버는 Mysql 엔진과 스토리지 엔진으로 구분된다. 스토리지 엔진은 핸들러 API를 만족시키면 누구든지 스토리지 엔진을 구현해 MYSQL 서버에서 사용할 수 있다.
4.1 Mysql 엔진 아키텍처
기본적인 Mysql 엔진 구조는 다음과 같다. Mysql 엔진 구조는 다른 DBMS 구조와 다르기 때문에 다른 DBMS에는 없는 이점을 가진다. 반대로 다른 DBMS에 없는 문제가 생기기도 한다.
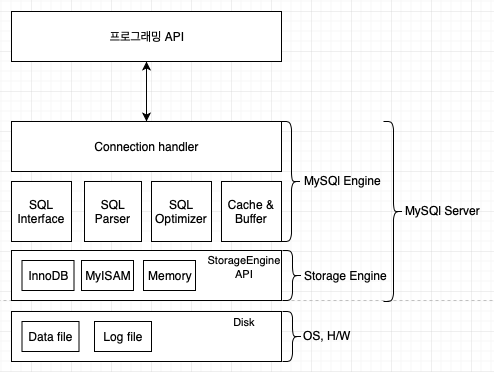
Mysql은 표준 SQL(ANSI SQL) 문법을 지원하기 때문에 표준 문법에 따라 작성된 쿼리가 다른 DBMS와 호환돼 실행될 수 있다. Mysql 엔진은 SQL 문장 분석과 최적화 등 역할을 한다. 실질적으로 데이터를 가져오는 역할은 스토리지 엔진이 전담한다. Mysql에서는 한 번에 여러 종류의 스토리지 엔진을 사용할 수 있다(ex - CREATE TABLE (...) ENGINE=INNODB;).
핸들러 API
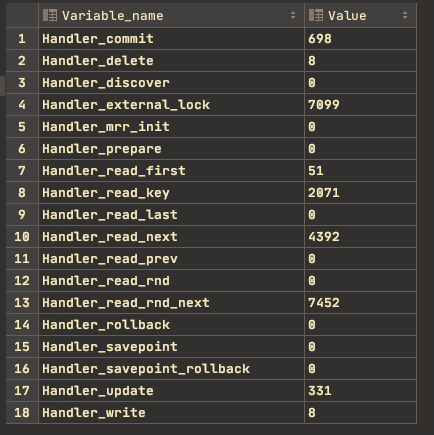
Mysql 엔진의 쿼리 실행기에서 데이터를 I/O 할 때 이를 스토리지 엔진에 요청한다. 이 요청을 핸들러 요청이라 하고 여기에 사용되는 API가 핸들러 API다. 아래 쿼리문을 통해 지금까지 사용한 핸들러 API를 이용해 작업한 데이터 양을 확인할 수 있다.
|
1
|
SHOW GLOBAL STATUS LIKE 'Handler%';
|
cs |
Mysql 스레딩 구조
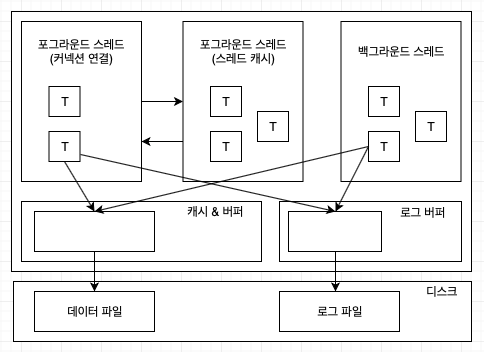
Mysql 서버는 스레드 기반이며 크게 포그라운드 스레드와 백그라운드 스레드로 나뉘어있다. Mysql 서버에서 실행 중인 스레드의 목록은 다음 쿼리를 통해 확인할 수 있다.
|
1
|
SELECT thread_id, name, type, processlist_user, processlist_host FROM performance_schema.threads ORDER BY type, thread_id;
|
cs |
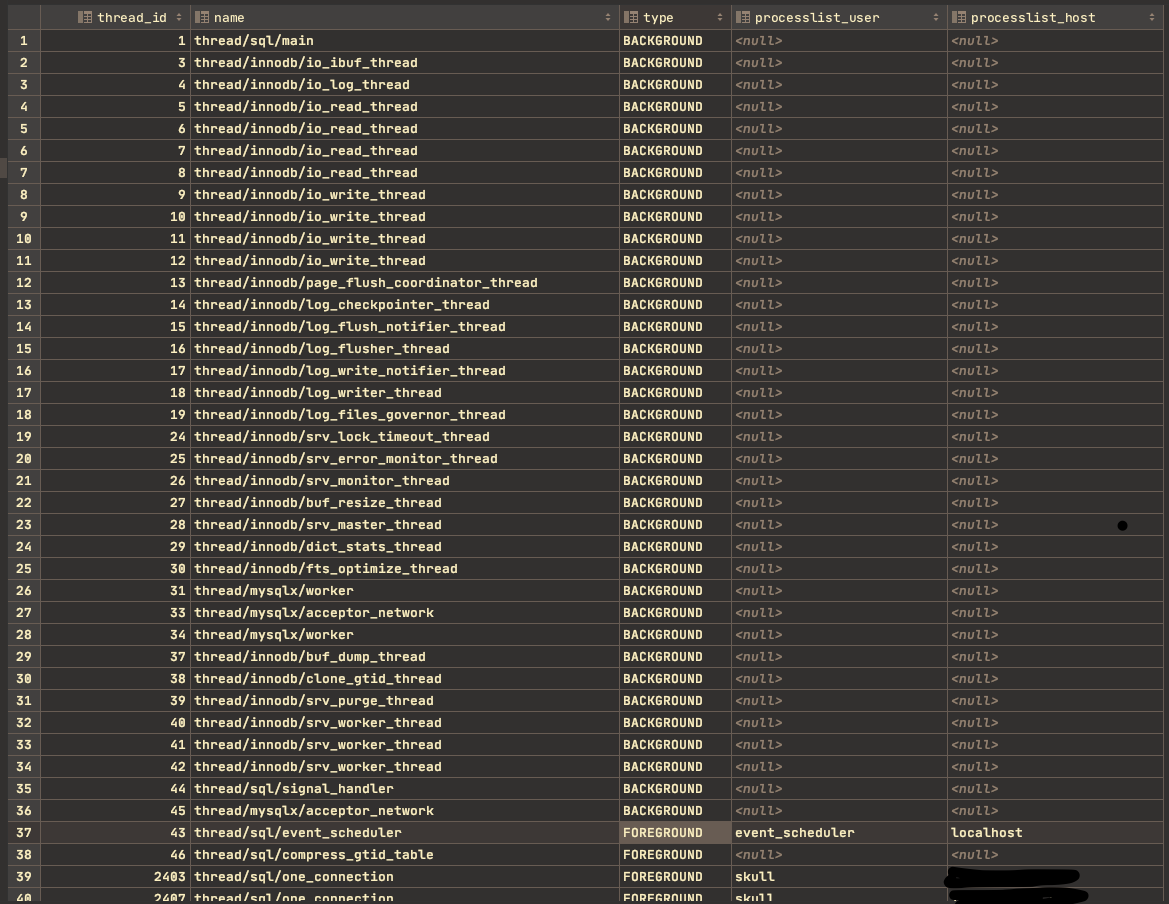
위 스레드 중 thread/sql/one_connection 만이 실제 사용자의 요청을 처리하는 스레드다. 백그라운드 스레드 개수는 Mysql 설정에 따라 가변적이다. 동일 이름의 스레드가 여러 개 존재하는 것은 Mysql 서버 설정 내용으로 인해 스레드가 동일 작업을 병렬로 처리하는 경우다.
포그라운드 스레드(클라이언트 스레드, 사용자 스레드)
포그라운드 스레드는 최소한 Mysql에 접속한 클라이언트 개수만큼 존재한다. 주로 클라이언트가 요청한 쿼리 문장을 처리한다. 커넥션이 종료되면 스레드는 스레드 캐시로 돌아간다. 이때, 스레드 캐시에서 대기 중인 스레드 수가 일정 개수 이상이면 스레드를 종료시킨다. 스레드 캐시에 유지할 수 있는 최대 스레드 개수는 thread_cache_size 시스템 변수로 설정할 수 있다.
포그라운드 스레드는 데이터를 Mysql의 데이터 버퍼나 캐시에서 가져온다. 만약 여기에 데이터가 없다면 직접 디스크나 인덱스 파일로부터 데이터를 읽어온다. MyISAM 테이블은 디스크 쓰기도 포그라운드 스레드가 처리하지만 InnoDB 테이블은 이를 백그라운드 스레드가 처리한다. InnoDB 테이블 포그라운드 스레드는 데이터 버퍼, 캐시까지만 담당한다.
백그라운드 스레드
InnoDB는 다음과 같은 작업을 백그라운드로 처리한다.
- Insert buffer를 병합하는 스레드 (thread/innodb/io_ibuf_thread)
- 로그를 디스크로 기록하는 스레드 (thread/innodb/io_log_thread)
- InnoDB 버퍼 풀의 데이터를 디스크에 기록하는 스레드 (thread/innodb/page_cleaner_thread)
- 데이터를 버퍼로 읽어오는 스레드 (thread/innodb/io_read_thread)
- 잠금이나 데드락을 모니터링하는 스레드
위 스레드 중 쓰기 스레드(Write thread)가 가장 중요하다. 쓰기 스레드는 로그 스레드와 버퍼의 데이터를 디스크에 쓰는 작업을 한다. MySql 5.5부터 데이터 I/O를 담당하는 스레드 개수를 각각 설정할 수 있다. InnoDB에서 읽기 작업은 클라이언트 스레드에서 처리되기에 많은 읽기 스레스 드를 설정할 필요가 없다. 하지만 쓰기 스레드는 많은 작업을 백그라운드로 처리하기 때문에 내장 디스크를 사용할 때는 2~4 정도, DAS나 SAN 같은 스토리지 사용 시 가능한 충분히 설정하는 것이 좋다. I/O스레드 개수 설정은 각각 innodb_write_io_threads와 innodb_read_io_threads 시스템 변수로 설정할 수 있다.
사용자 요청을 처리할 때 데이터의 쓰기 작업은 지연될 수 있지만 읽기는 지연될 수 없다. InnoDB를 포함한 일반적인 상용 DBMS는 쓰기를 버퍼링 해 일괄 처리한다. 반면, MyISAM은 사용자 스레드가 쓰기 작업까지 함께 처리한다. 이 때문에 InnoDB는 INSERT, UPDATE, DELETE로 인해 데이터가 변경되는 경우 데이터가 디스크의 데이터 파일로 저장될 때까지 기다리지 않아도 된다. 하지만 MyISAM에서 일반적인 쿼리는 쓰기 버퍼링 기능을 사용할 수 없다.
메모리 할당 및 사용 구조
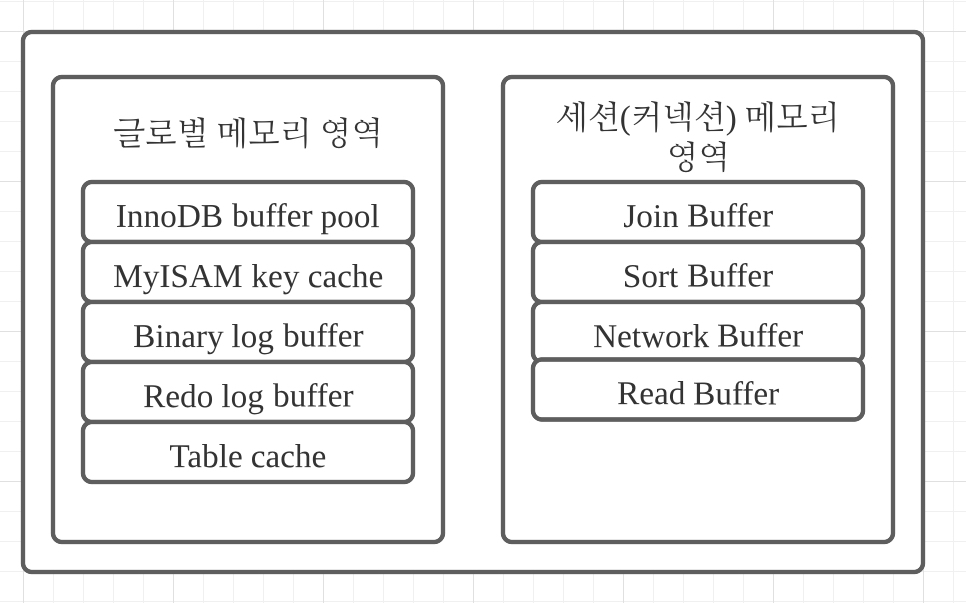
MySQL이 사용하는 메모리 공간은 글로벌 메모리 영역과 로컬 메모리 영역으로 나뉜다. 글로벌 메모리 영역은 MySQL 서버가 시작되면 할당된다. 이때, 요청된 메모리 공간이 한 번에 모두 할당되는지, 필요할 때마다 필요한 만큼을 할당해 주는지는 운영체제마다 다르다. MySQL이 사용하는 메모리 양을 측정하는 것은 쉽지 않으므로, 단순하게 MySQL의 시스템 변수로 설정해 둔 만큼 운영체제로부터 메모리를 할당받는다.
글로벌 메모리 영역과 로컬 메모리 영역의 차이는 여러 스레드가 공유해서 사용하는지 여부에 따라 다르다.
글로벌 메모리 영역
글로벌 메모리 영역은 스레드 개수와 무관하게 하나의 메모리 공간만 할당된다. 두 개 이상의 메모리 공간을 할당받을 수도 있지만 이 역시 스레드 개수와 무관하다. 할당된 모든 공간은 모든 스레드에 의해 공유된다.
로컬 메모리 영역
MySQL 서버에 존재하는 클라이언트 스레드가 쿼리를 처리하는 데 사용하는 메모리 영역이다. 클라이언트 하나가 MySQL 서버에 접속하면 MySQL 서버는 클라이언트 커넥션으로부터의 요청을 처리하기 위해 스레드를 하나 할당한다. 여기서 클라이언트 스레드가 사용하는 메모리 공간이 로컬 메모리 영역이라 클라이언트 메모리 영역이라고도 한다. 또 한, 클라이언트와 MySQL 서버 간의 커넥션을 세션이라 하므로 세션 메모리 영역이라고도 한다.
로컬 메모리 영역은 각 클라이언트 스레드 별로 할당되어 상호 독립적이다. 일반적으로 메모리 설정 시 글로벌 메모리 영역의 크기만 신청 쓰는데 최악의 경우 MySQL 서버가 메모리 부족으로 멈출 수도 있으므로 적절한 메모리 공간을 설정해야 한다. 로컬 메모리 영역은 각 쿼리의 용도별로 필요할 때만 공간이 할당된다. 따라서 로컬 메모리 공간은 커넥션이 열려 있는 동안 계속해서 할당된 상태로 남아있는 공간이 있고(커넥션 버퍼, 결과 버퍼) 쿼리를 실행하는 순간에만 할당했다가 헤제하는 공간(소트 버퍼, 조인 버퍼)이 있다.
플러그인 스토리지 엔진 모델
MySQL은 플러그인 모델이라는 독특한 모델을 사용한다. 그 때문에 스토리지 엔진뿐만 아니라 전문 검색 엔진을 위한 검색어 파서, 사용자 인증을 위한 Native Authentication 등을 모두 플러그인으로 제작할 수 있다. MySQL은 이미 수많은 스토리지 엔진을 가지고 있지만, 사용자 요구사항 만족을 위해 다른 스토리지 엔진을 개발하는 것도 가능하다.
MySQL에서 쿼리가 실행되는 개략적인 과정은 다음과 같다.

이 과정에서 볼 수 있듯 마지막 Data I/O 부분만 스토리지 엔진에 의해 처리된다. 따라서 사용자가 새로운 스토리지 엔진을 만든다 해도 DBMS의 전체 기능이 아닌 일부분의 기능만 수행하는 엔진을 작성하게 된다.
위 과정에서 Data I/O과정은 대부분 1건의 레코드 단위로 처리된다.
MySQL을 사용하다 보면 핸들러라는 단어가 종종 등장한다. 프로그래밍 언어에서 어떤 기능을 호출하기 위해 그 기능에 매핑을 시켜주는 역할을 하는 객체를 핸들러라 한다. MySQL 서버에서는 MySQL 엔진이 스토리지 엔진을 조정하기 위해 핸들러를 사용한다. 따라서 MySQL 엔진이 각 스토리지 엔진에게 데이터 I/O 명령을 하기 위해선 반드시 핸들러를 통해야 한다.
MySQL에서 다양한 스토리지 엔진을 사용하는 테이블에 대해 쿼리를 실행해도 MySQL의 처리 내용은 대부분 동일하다. 단순히 데이터 I/O 영역에만 차이가 존재한다. 또 한, GROUP BY나 ORDRE BY 등 복잡한 처리는 스토리지 엔진 영역이 아닌 MySQL 엔진의 쿼리 실행기에서 처리된다. Data I/O 방식에 따라서 작업 처리 방식이 얼마나 변하는지는 추후에 차차 설명하자. 여기서는 하나의 쿼리 작업이 여러 하위 작업으로 나뉘고, 각 하위 작업이 어느 영역에서 처리되는지 구분할 줄 하는 게 핵심이다.
이제 설치된 MySQL 서버에서 지원하는 스토리지 엔진 종류를 살펴보자.
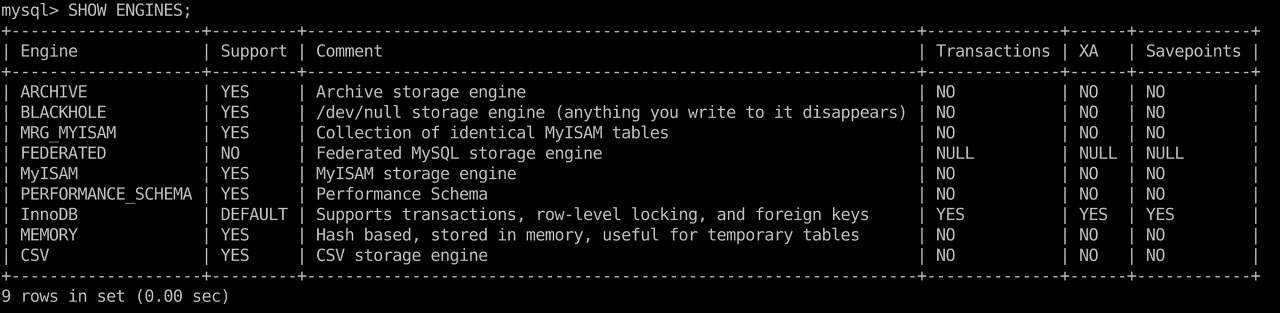
위 Support Column에 표시될 수 있는 값은 다음과 같다.
- YES: MySQL 서버에 해당 스토리지 엔진이 포함돼 있고, 사용 가능으로 활성화된 상태
- DEFAULT: ‘YES’와 동일한 상태지만 필수 스토리지 엔진임을 의미한다(즉, 스토리지 엔진이 없으면 MySQL이 시작되지 않을 수도 있다)
- NO: 현재 MySQL 서버에 포함되지 않음을 의미한다.
- DISABLED: 현재 MySQL 서버에는 포함됐지만 파라미터에 의해 비활성화된 상태
만약 Support 항목에 NO인(MySQL 서버에 포함되지 않은) 스토리지 엔진을 사용하려면 MySQL 서버를 재 빌드해야 한다. 하지만 MySQL 서버가 포함하고 있는 엔진이라면 플러그인 형태로 빌드된 스토리지 엔진 라이브러리를 다운로드해 끼워 넣기만 하면 된다.
모든 플러그인 항목을 확인해보자.
|
1
|
SHOW PLUGINS;
|
cs |
MySQL은 MySQL 서버 기능을 확장할 수 있게 플러그인 API가 매뉴얼에 공개돼 있다. 따라서 기존에 재공 하는 기능을 확장하거나 완전히 새로운 기능들을 구현할 수 있다. MySQL 플러그인 매뉴얼
컴포넌트
MySQL 8.0부터는 플러그인 아키텍처 대신 컴포넌트 아키텍처를 지원한다. MySQL 서버의 플러그인은 다은과 같은 단점들을 가진다.
- 플러그인은 오직 MySQL 서버와 통신할 수 있고 플러그인끼리는 통신할 수 없다.
- 플러그인은 MySQL 서버의 변수나 함수를 직접 호출하기 때문에 안전하지 않다(캡슐화 안됨)
- 플러그인은 상호 의존 관계를 설정할 수 없어서 초기화가 어렵다.
컴포넌트를 설치하면 플러그인과 마찬가지로 새로운 시스템 변수를 설정해야 할 수도 있다. MySQL 서버에서 기본으로 제공되는 컴포넌트에 대한 설명은 MySQL 컴포넌트 매뉴얼을 참고하자.
쿼리 실행 구조
쿼리 실행 과정을 간략화하면 다음과 같다. 아래 과정에서 각 부분은 다음과 같은 역할을 한다.
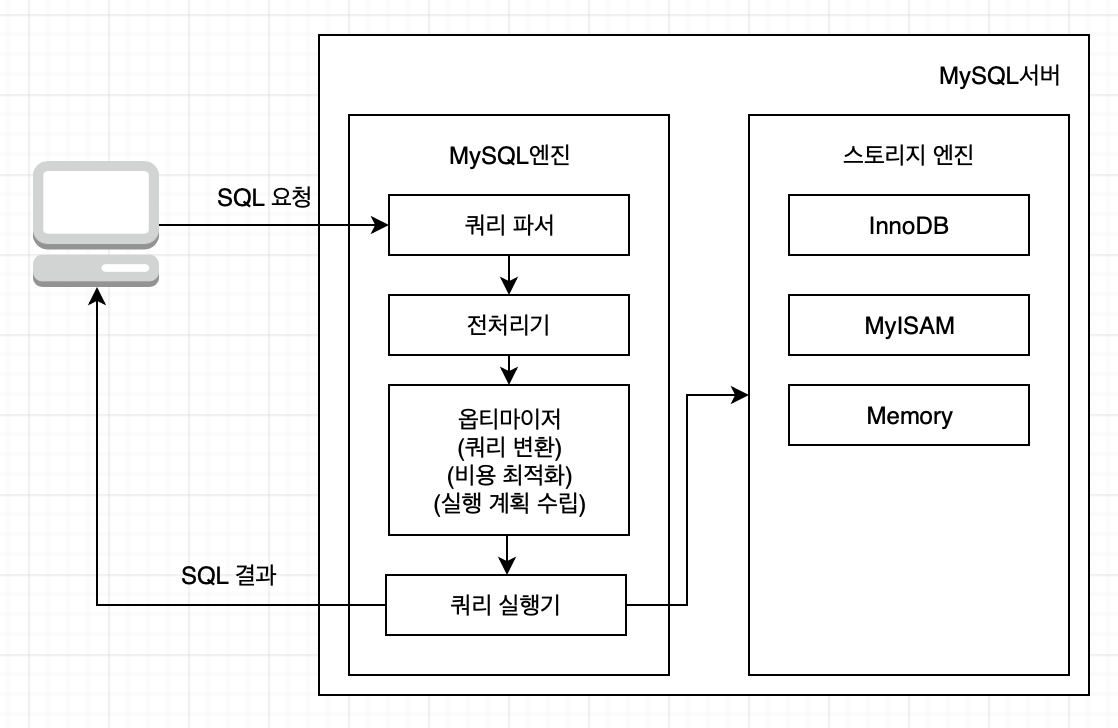
쿼리 파서
사용자 요청으로 들어온 쿼리 문장을 토큰(MySQL이 인식할 수 있는 최소 단위의 어휘나 기호)으로 분리해 트리 형태의 구조로 만들어 내는 작업이다. 쿼리 문장의 문법적 오류가 발견되면 사용자에게 오류 메시지를 전달한다.
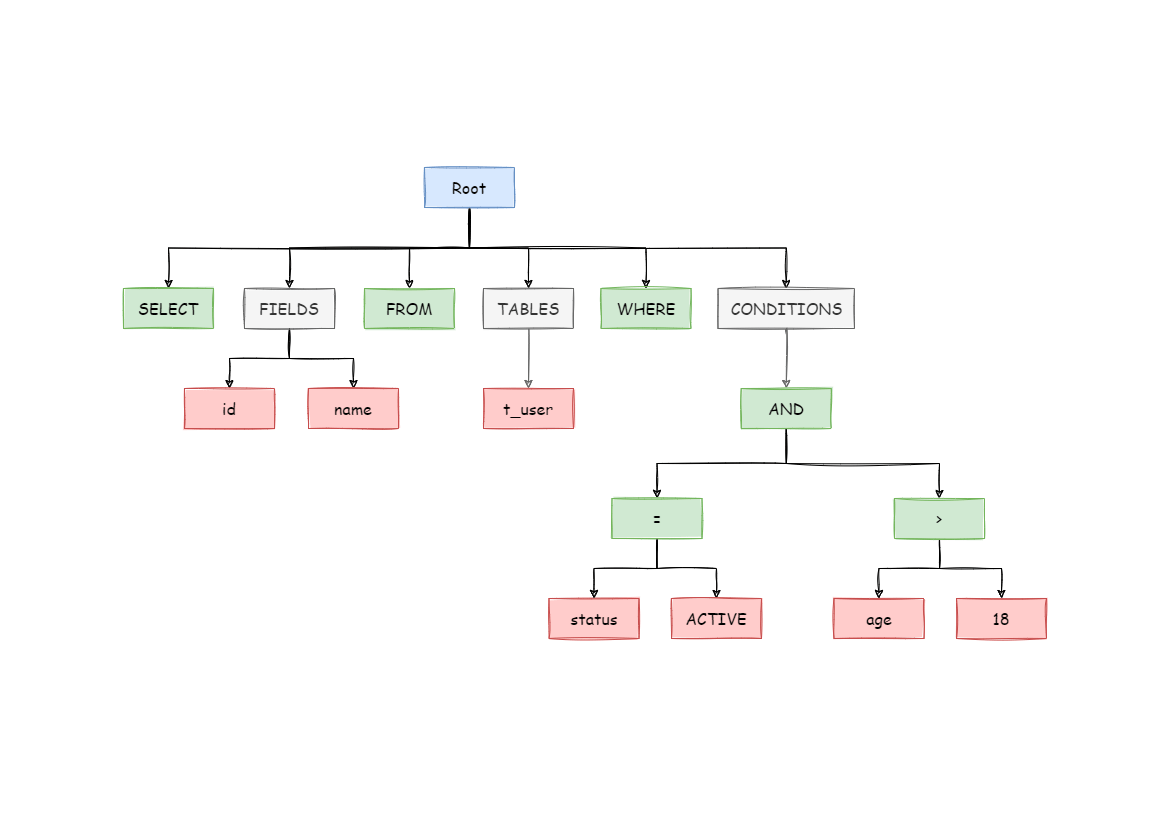
예를 들어 다음과 같은 SQL 문은
|
1
|
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
|
cs |
쿼리 파서에서 파싱을 거치면 다음과 같은 트리 구조가 된다.
전처리기
파서 과정에서 만들어진 파서 트리를 기반으로 쿼리 문장에 구조적인 문제점이 있는지 확인한다. 각 토큰을 테이블 이름, 칼럼 이름, 내장 함수 같은 개체를 매핑해 객체의 존재 여부와 접근 권한 등을 확인한다. 존재하지 않거나 권한상 사용할 수 없는 개체의 토큰을 거른다.
옵티마이저
사용자의 요청으로 들어온 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할지를 결정한다. DBMS의 두뇌에 해당한다.
실행 엔진
실행 엔진은 만들어진 계획대로 각 핸들러에게 요청해서 받은 결과를 또 다른 핸들러 요청의 입력으로 연결하는 역할을 한다. 예를 들어 옵티마이저가 GROUP BY를 처리하기 위해 임시 테이블을 만드는 과정은 다음과 같다
1. 실행 엔진이 핸들러에게 임시 테이블을 만들라고 요청
2. 다시 실행 엔진은 WHERE 절에 일치하는 레코드를 읽어오라고 핸들러에게 요청
3. 읽어온 레코드들을 1번에서 준비한 임시 테이블로 저장하라고 핸들러에게 요청
4. 데이터가 준비된 임시 테이블에서 필요한 방식으로 데이터를 읽어오라고 핸들러에게 다시 요청
5. 최종적으로 실행 엔진은 결과를 사용자나 다른 모듈로 넘김
핸들러(스토리지 엔진)
핸들러는 MySQL 서버의 가장 밑단에서 MySQL 실행 엔진 요청에 따라 데이터를 디스크에 I/O 하는 역할을 한다. 따라서 핸들러는 결국 스토리지 엔진이다.
쿼리 캐시
쿼리 캐시는 SQL 실행 결과를 캐싱해 동일 쿼리가 실행되면 테이블을 읽지 않고 즉시 결과를 반환하기 때문에 성능이 좋다. 하지만, 원본이 변경되면 그에 대응하는 캐싱 데이터를 삭제(Invalidate) 하기 때문에 심각한 동시 처리 성능 저하를 유발한다. 또 한, MySQL 서버가 발전하면서 성능이 개선되는 과정에서 쿼리 캐시는 동시 처리 성능 저하, 버그의 원인이 되었다.
위 같은 이유 때문에 MySQL 8.0부터 쿼리 캐시 기능을 지원하지 않는다.
스레드 풀
MySQL 서버 엔터프라이즈는 스레드 풀을 제공하지만 커뮤니티 에디션은 지원하지 않는다. 따라서 엔터프라이즈 버전의 스레드 풀이 아닌 Percona Server에서 제공하는 스레드 풀을 살펴보자.
Percona Server의 스레드 풀은 플러그인 형태로 작동한다. 따라서 커뮤 니버전에서 동일 버전의 Percona Server에서 스레드 풀 플러그인 라이브러리(thread_pool.so)를 설치해서 스레드 풀을 사용할 수 있다.
스레드 풀의 목적은 사용자의 요청을 처리하는 스레드 개수를 줄여서 MySQL 서버의 CPU가 제한된 개수의 스레드 처리에만 집중할 수 있게 해서 서버의 자원 소모를 줄이는 대에 있다. 하지만 단순히 스레드 풀을 설치하는 것만으로는 큰 성능 향상을 기대하기 어렵다. 스레드 풀은 앞에서 말했듯 동시에 실행 중인 스레드들을 CPU가 최대한 잘 처리해낼 수 있는 수준으로 줄여서 빨리 처리하게 하는 것이 목표다. 여기서 만약 스케줄링 과정에서 CPU 시간을 올바르게 확보하지 못하면 쿼릴 처리가 더 느려지는 사례가 발생한다. 물론 적절한 수의 스레드로 CPU가 사용자 요청을 처리한다면 프로세서 친화도(Processor affinity)를 놓이고 불필요한 콘텍스트 스위치를 줄일 수 있다.
Persona Server의 스레드 풀은 기본적으로 CPU 코어의 개수만큼 스레드 그룹을 생성한다. 스레드 그룹의 개수는 thread_pool_size 시스템 변수를 변경해 조정할 수 있다. 일반적으로 CPU 코어 개수와 맞추는 것이 CPU 프로세스 친화도를 높이는 데 좋다. MySQL 서버가 처리해야 할 요청이 생기면 스레드 풀로 처리를 이관한다. 만약 이미 스레드 풀에서 처리 중인 작업이 있다면 thread_pool_oversubscribe 시스템 변수(deafult 3)에 설정된 개수만큼 추가로 더 받아 처리한다. 이 값이 너무 크면 스케줄링해야 할 스레드가 많아져서 스레드 풀이 비효율적으로 동작한다.
스레드 그룹의 모든 스레드가 일을 처리하고 있다면 스레드 풀을 해당 스레드 그룹에 새로운 워커 스레드를 추가할지 결정해야 한다. 스레드 풀의 타이머 스레드는 주기적으로 스레드 그룹의 상태를 체크해서 thread_pool_stall_limit 시스템 변수에 정의된 밀리초만큼 작업 스레드가 작업을 끝내지 못하면 새로운 스레드를 생성해 스레드 그룹에 추가한다. 이때, 스레드 풀에 있는 전체 스레드 개수는 thread_pool_max_threads 시스템 변수에 설정된 개수를 넘어설 수 없다.
Percona Server의 스레드 풀은 선순위 큐와 후순위 큐를 이용해 특정 트랜잭션이나 쿼리를 우선적으로 처리할 수 있는 기능도 제공한다. 이를 통해 시작된 트랜잭션 내에 속한 SQL을 빨리 처리해 해당 트랜잭션이 가지고 있던 락을 빨리 해제해 락 경합을 낮춰서 전체적인 처리 성능을 향상할 수 있다.
트랜잭션 지원 메타데이터
데이터베이스 서버에서 테이블 구조 정보와 스토어드 프로그맨 등의 정보를 데이터 딕셔너리 또는 메타데이터라 한다. MySQL 서버는 5.7까지 테이블 구조를 FRM 파일에 저장하고 일부 스토어드 프로그램 역시 파일 기반으로 관리한다. 그 때문에 메타데이터 생성, 변경 작업이 트랜잭션을 지원하지 않아 테이블 생성 또는 변경 도중 MySQL 서버가 비정상 종료되면 일관되지 않는 상태로 남는 문제가 있었다. 이를 흔히 '데이터베이스나 테이블이 깨졌다'라고 한다.
위 문제를 해결하기 위해 MySQL 8.0부터는 테이블 구조 정보, 스토어드 프로그램의 코드 관련 정보를 모두 InnoDB의 테이블에 저장한다. MySQL 서버가 장동하는 데 필요한 테이블들을 묶어서 시스템 테이블이라 한다. 시스템 테이블과 딕셔너리 정보는 모두 mysql DB에 저장하고 있다. mysql DB는 통쨰로 mysql.ibd라는 이름의 테이블스페이스에 저장된다. 이로 인해 스키마 변경 작업 중에 MySQL 서버가 비정상적으로 종료돼도 원자성을 보장한다.
MySQL 서버에서 InnoDB를 제외한 다른 스토리지 엔진의 메타 정보는 여전히 저장할 공간이 필요하다. 이를 위해 MySQL은 SDI(Serialized Dictionary Information, *. sdi) 파일을 사용한다. 이 파일들은 기존의 *. RFM 파일과 동일한 역할을 한다. SDI는 직렬화를 위한 포맷이므로 InnoDB 테이블 구조도 SDI 파일로 변환할 수 있다. ibd2 sdi 유틸리티를 사용하면 InnoDB 테이블스페이스에서 스키마 정보를 추출할 수 있다.
출처 - Real MySQL 1