스프링 배치는 배치 수행과 관련된 수치 데이터와 잡의 상태를 JobRepository를 이용해 유지 관리한다. 그리고 잡이 재시작 또는 아이템 재처리 시 어떤 동작을 수행할지 이 정보를 사용해 결정한다. JobRepository는 배치와 관련된 메타데이터를 저장하는 데이터 저장소이다. 이 저장소는 인메모리 저장소와 관계형 데이터베이스 형태로 제공된다.
관계형 데이터베이스 저장소
관계형 데이터베이스 방식에서는 스프링 배치가 제공하는 여러 테이블을 이용해 배치 메타데이터를 저장한다.
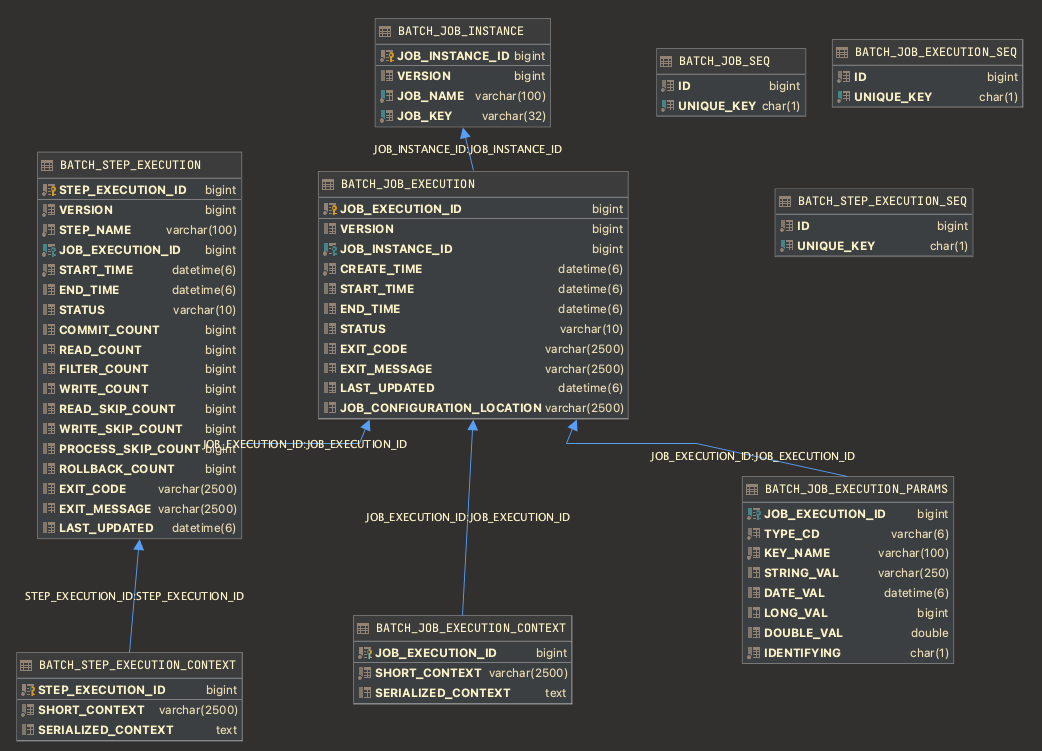
BATCH_JOB_INSTANCE
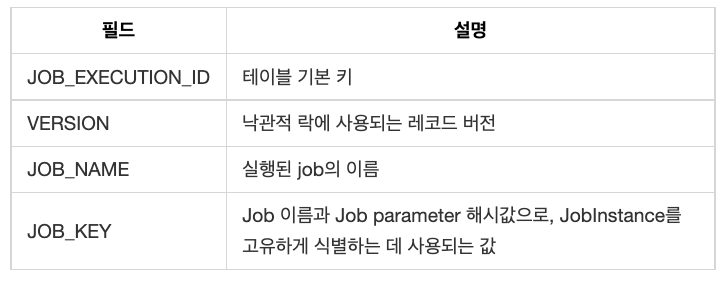
이 스키마의 시작점은 BATCH_JOB_INSTANCE이다. job을 식별하는 고유 정보가 포함된 job parameter로 job을 처음 실행하면 JobInstance 레코드가 테이블에 삽입된다. BATCH_JOB_INSTANCE 구조는 다음과 같다.
BATCH_JOB_EXECUTION
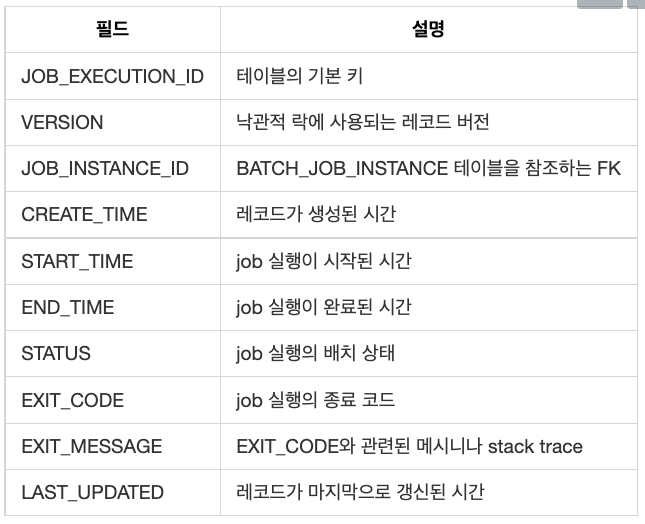
BATCH_JOB_EXECUTION은 배치 job의 실제 실행 기록이다. job이 실행될 때마다 새 레코드가 삽입되고 job이 실행되는 동안 주기적으로 업데이트된다.
BATCH_JOB_EXECUTION 구조는 다음과 같다.
 스프링 배치가 제공하는 테이블 중 다음 3개의 테이블이 BATCH_JOB_EXECUTION 테이블과 관련 있다.
스프링 배치가 제공하는 테이블 중 다음 3개의 테이블이 BATCH_JOB_EXECUTION 테이블과 관련 있다.
- BATCH_JOB_EXECUTION_CONTEXT
- BATCH_JOB_EXECUTION_PARAMS
- BATCH_STEP_EXECUTION
BATCH_JOB_EXECUTION_CONTEXT
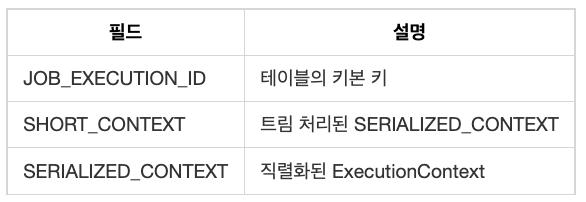
BATCH_JOB_EXECUTION_CONTEXT는 JobExecution의 ExecutionContext를 저장한다. 재시작처럼 배치가 여러 번 실행되는 상황에서 ExecutionContext 정보 재사용을 위해 저장된다.
BATCH_JOB_EXECUTION_CONTEXT 구조는 다음과 같다.
 스프링 배치 버전 4 이전까지는 ExecutionContext 직렬화를 위해 XStream의 JSON 처리 기능을 기본으로 사용했다. 그러나 지원하는 기능의 제약으로 인해 버전 4부터는 Jackson2를 기본적으로 사용한다.
스프링 배치 버전 4 이전까지는 ExecutionContext 직렬화를 위해 XStream의 JSON 처리 기능을 기본으로 사용했다. 그러나 지원하는 기능의 제약으로 인해 버전 4부터는 Jackson2를 기본적으로 사용한다.
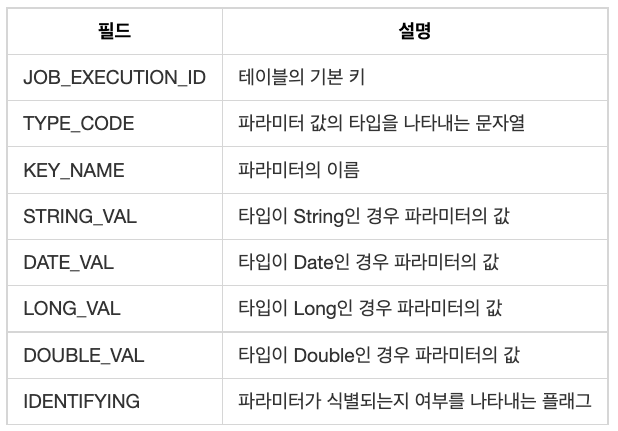
BATCH_JOB_EXECUTION_PARAMS
job이 매번 실행될 때마다 사용된 job parameter를 저장한다. job 재시작 시에는 잡의 식별 정보 파라미터만 자동으로 전달된다.
BATCH_JOB_EXECUTION_PARAMS 구조는 다음과 같다.
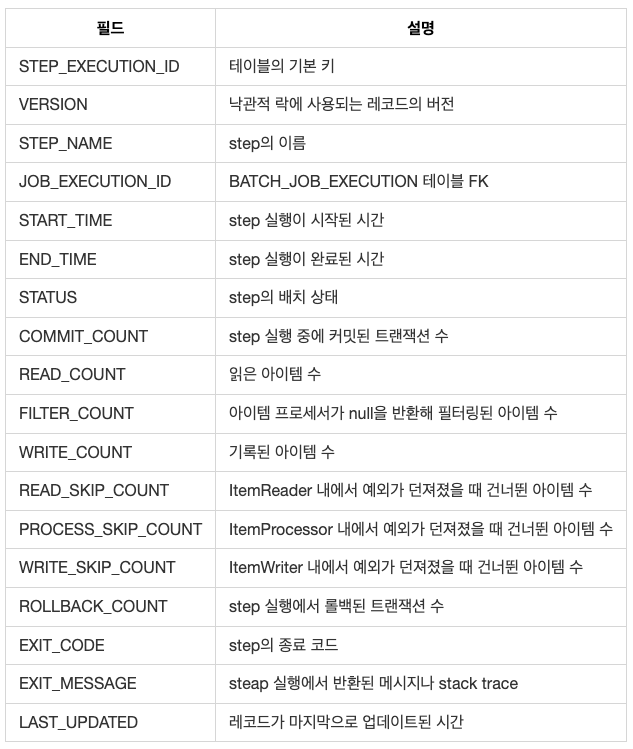
BATCH_STEP_EXECUTION
step의 메타데이터를 저장한다. Step의 시작, 완료, 상태에 대한 메타데이터와 스텝 분석을 위한 다양한 횟수 값을 추가로 저장한다.
BATCH_STEP_EXECUTION 구조는 다음과 같다.
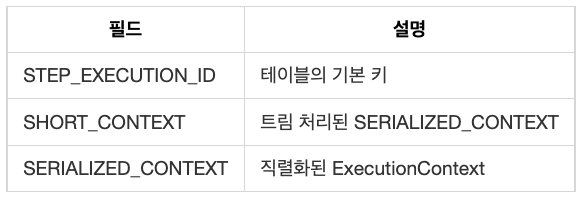
BATCH_STEP_EXECUTION_CONTEXT
StepExecution 내의 ExecutionContext는 step 수준에서 컴포넌트 상태를 저장한다. BATCH_STEP_EXECUTION_CONTEXT는 이 ExecutionContext를 저장한다.
Batch_STEP_EXECUTION_CONTEXT 구조는 다음과 같다.
XXX_SEQ
위에서 설명한 테이블 외에도 “_SEQ”로 끝나는 테이블이 3개 존재한다. 이 테이블은 각각 BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION, BATCH_STEP_EXECUTION 테이블의 “_ID”로 끝나는 컬럼과 관련 있다. “_ID”로 끝나는 컬럼은 테이블의 PK로 사용되지만 데이터베이스가 제공하는 방식으로 만들어진 PK를 사용하진 않는다. 대신 별도의 sequence로 만들어진 키를 사용한다. 이런 방식을 사용하는 이유는 도메인 객체를 데이터베이스에 저장한 뒤에도 해당 키를 이용해 java 단에서 객체를 식별하기 위해서다. 물론 JDBC가 3.0부터 이 기능을 제공하긴 하지만 여전히 “_SEQ”테이블을 사용하고 있다. JobExecution의 경우 다음과 같은 과정으로 id를 할당하고 BATCH_JOB_EXECUTION에 저장한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
// SimpleJobRepository.java
// createJobExecution() 내부에서 JdbcJobExecutionDao 호출
public class SimpleJobRepository implements JobRepository {
...
@Override
public JobExecution createJobExecution(String jobName, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {
...
/*
* Find all jobs matching the runtime information.
*
* If this method is transactional, and the isolation level is
* REPEATABLE_READ or better, another launcher trying to start the same
* job in another thread or process will block until this transaction
* has finished.
*/
JobInstance jobInstance = jobInstanceDao.getJobInstance(jobName, jobParameters);
ExecutionContext executionContext;
// existing job instance found
if (jobInstance != null) {
...
}
else {
// no job found, create one
...
}
JobExecution jobExecution = new JobExecution(jobInstance, jobParameters, null);
jobExecution.setExecutionContext(executionContext);
jobExecution.setLastUpdated(new Date(System.currentTimeMillis()));
// Save the JobExecution so that it picks up an ID (useful for clients
// monitoring asynchronous executions):
jobExecutionDao.saveJobExecution(jobExecution);
ecDao.saveExecutionContext(jobExecution);
return jobExecution;
}
...
}
// JdbcJobExecutionDao.java
public class JdbcJobExecutionDao extends AbstractJdbcBatchMetadataDao implements JobExecutionDao, InitializingBean {
...
@Override
public void saveJobExecution(JobExecution jobExecution) {
validateJobExecution(jobExecution);
jobExecution.incrementVersion();
// jobExecution의 id 지정
jobExecution.setId(jobExecutionIncrementer.nextLongValue());
Object[] parameters = ...
getJdbcTemplate().update(
getQuery(SAVE_JOB_EXECUTION),
parameters,
new int[] { Types.BIGINT, Types.BIGINT, Types.TIMESTAMP, Types.TIMESTAMP, Types.VARCHAR,
Types.VARCHAR, Types.VARCHAR, Types.INTEGER, Types.TIMESTAMP, Types.TIMESTAMP, Types.VARCHAR });
insertJobParameters(jobExecution.getId(), jobExecution.getJobParameters());
}
...
}