1. 분산 데이터베이스 시스템
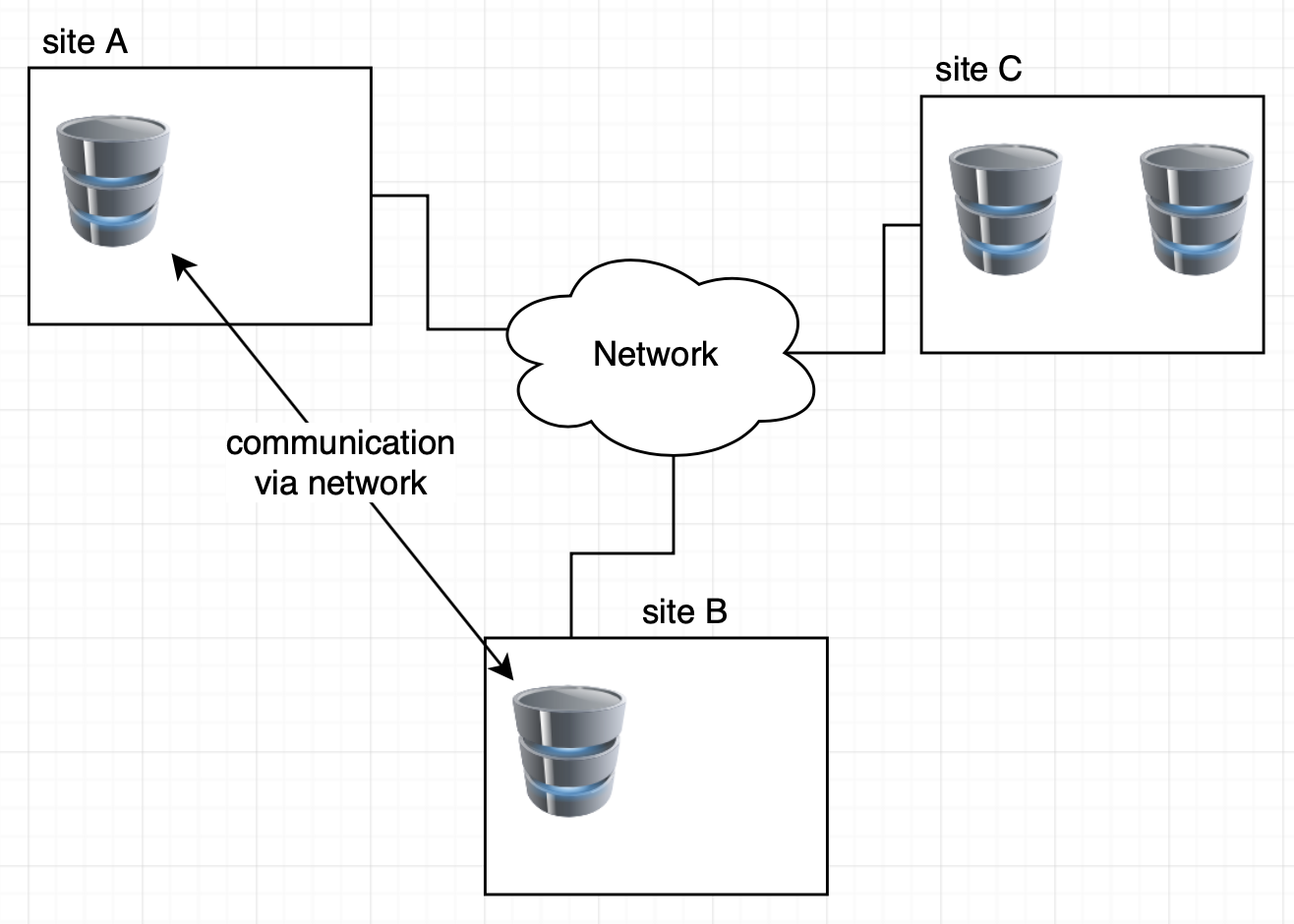
분산 데이터베이스 시스템에서는 각 노드가 메인 메모리나 디스크를 공유하지 않고 인터넷 같은 통신 매체를 통해 서로 통신한다.
 분산 데이터베이스는 다음과 같은 특성을 가진다.
분산 데이터베이스는 다음과 같은 특성을 가진다.
- 분산 데이터베이스는 지리적으로 떨어진 사이트를 갖기 때문에 단일 데이터 센터 내의 네트워크에 비해 다음과 같은 단점을 갖는다.
- 네트워크 연결의 대역폭이 낮다
- 대기 시간이 길다
- 장애가 발생할 가능성이 크다
- 때문에 물리적 위치와 장애, 네트워크 지연 시간 등에 주의해야 한다.
- 이는 분산 데이터베이스 노드가 WAN을 통해 통신하기 때문이다.
- WAN이 LAN보다 더 큰 대역폭을 가지긴 하나, WAN의 대역폭은 여러 사용자와 애플리케이션이 공유하기 때문에 실제 노드 간 사용되는 대역폭은 낮다.
- 또 한 광속 지역(speed-of-light delay)와 여러 라우터의 대기 지연(queuing delay)으로 메시지 전송에 최대 수 백 밀리초가 소요된다.
- WAN은 네트워크-링크 장애 문제가 발생할 수 있다. 이로 인해 두 사이트가 모두 살아있지만 서로 통신할 수 없는 네트워크 분할(network partition) 문제가 발생할 수 있다.
- 분산 데이터베이스 시스템은 높은 가용성을 보장하기 위해 전체 데이터 센터에 장애가 발생해도 계속 작동해야 한다. 따라서 자연재해가 모든 데이터 센터에 영향을 미치지 않게 지리적으로 떨어진 데이터 센터에 데이터를 복제해 두어야 한다.
- 분산 데이터베이스는 개별적으로 관리될 수 있고, 각 사이트는 일정 수준의 운영 자치성(autonomy)을 가진다. 즉, 각 사이트에서 지역적으로 저장된 데이터에 대해 일정 수준의 제어권을 갖는다. 중앙 집중 시스템은 중앙 사이트의 데이터베이스 관리자가 전체 데이터베이스를 제어한다. 반면 분산 시스템에선 전체 시스템을 책임지는 전역 데이터베이스 관리자와 책임 일부를 지는 각 사이트의 지역 데이터베이스 관리자가 존재한다. 분산 데이터베이스 시스템은 설계에 따라 각 관리자가 다른 수준의 지역 자치성(local autonomy)을 가질 수 있다.
- 분산 데이터베이스의 노드는 크기와 기능이 다양하다
- 분산 데이터베이스 시스템은 트랜잭션을 두 가지로 구분한다.
- 지역 트랜잭션(local transaction): 트랜잭션이 시작된 노드에서만 데이터에 접근한다
- 전역 트랜잭션(global transaction): 트랜잭션이 시작된 노드 이외의 다른 노드들의 데이터에 접근하는 트랜잭션
분산 데이터베이스 시스템은 두 가지 종류로 나뉜다.
- 동종 분산 데이터베이스(homogeneous distributed database): 시스템에서 노드는 공통의 전역 스키마를 공유하고, 모든 노드는 같은 분산 데이터베이스 관리 소프트웨어를 사용하며 트랜잭션 및 질의 처리에도 적극적으로 협력한다.
- 이종 분산 데이터베이스 시스템(heterogeneous distributed database system): 각자 고유한 스키마가 존재하고 서로 다른 데이터베이스 관리 소프트웨어를 구동할 수 있다. 사이트는 다른 사이트를 인식하지 못할 수 있고, 질의 및 트랜잭션 처리 협력을 위한 제한된 기능만 제공한다.
2. 분산 시스템의 트랜잭션 처리
트랜잭션의 원자성은 분산 데이터베이스 시스템을 구축하는 데 중요한 문제다. 만일 어떤 트랜잭션이 두 노드에 걸쳐서 동작하는 경우, 시스템 설계자가 주의를 기울이지 않으면 한 노드에서 커밋을, 다른 노드에서 중단을 수행해서 일관되지 않은 상태를 유발할 수 있다.
전역 트랜잭션은 여러 노드가 트랜잭션 처리에 참여하고 있기 때문에 ACID를 보장하는 것이 훨씬 복잡하다.
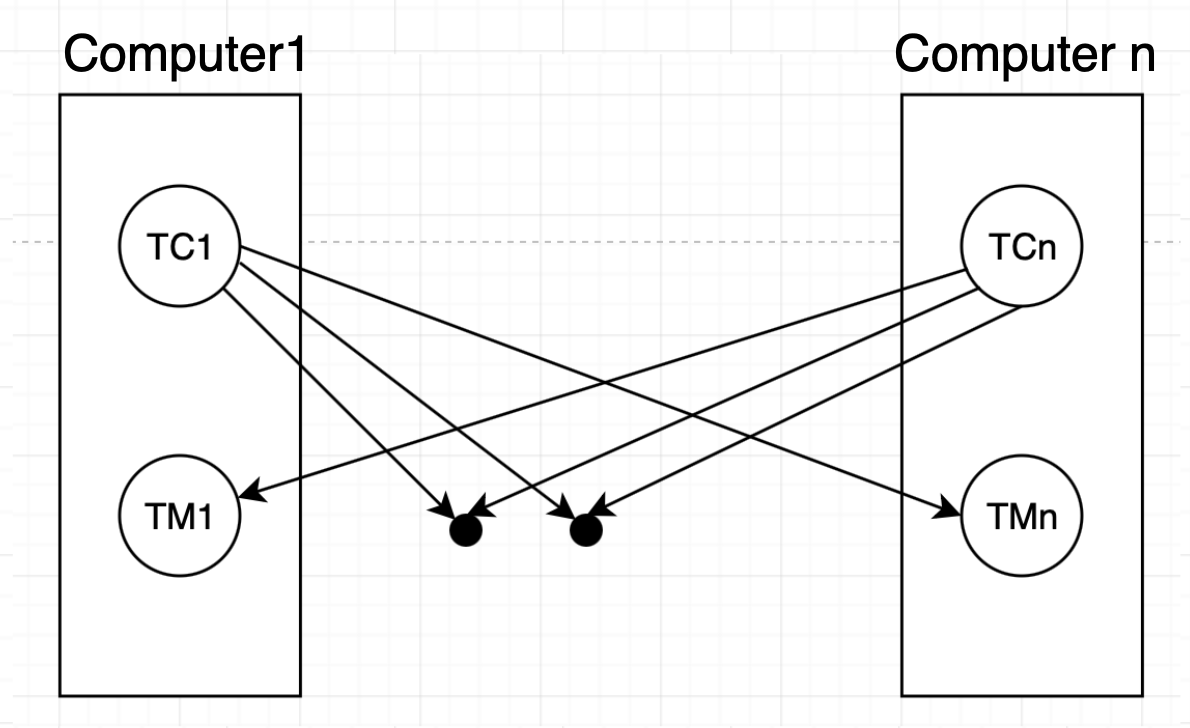
여러 노드로 구성된 시스템 구조에선 각 노드가 다른 노드와 무관하게 실패할 수 있다. 각 노드는 고유의 지역 트랜잭션 관리자를 가지고 각 노드에서 실행된 트랜잭션에 대해 ACID를 보장하는 역할을 한다. 여러 지역 트랜잭션 관리자는 전역 트랜잭션을 수행하기 위해 서로 협력한다. 이 관리자는 다음과 같은 두 개의 하위 시스템을 가지며 각 하위 시스템의 역할은 다음과 같다.
- 트랜잭션 관리자(transaction manager): 해당 노드에 있는 데이터에 접근하는 트랜잭션의 실행을 관리한다. 각 트랜잭션은 지역 트랜잭션 또는 전역 트랜잭션이다.
- 복구를 위한 로그 관리
- 해당 노드에서 수행하는 트랜잭션의 동시 실행을 조정하기 위해 적절한 동시성 제어 기법에 참여하기
- 트랜잭션 조정자(transaction coordinator): 해당 노드에서 시작된 다양한 트랜잭션의 실행을 조정한다.
- 트랜잭션을 시작하는 것
- 시작된 트랜잭션을 여러 개의 하위 트랜잭션으로 분리하고 적절한 노드에 분배하는 것
- 트랜잭션의 종료를 관리하는 것, 즉 참여한 모든 노드에서 커밋 되거나 혹은 중단되도록 한다.
2.2 시스템 실패 상태
분산 시스템은 다음과 같은 오류가 발생할 수 있다.
- 소프트웨어 오류
- 하드웨어 오류
- 메시지 손실
- 통신 경로의 실패
- 네트워크 분할(두 노드 간 경로 완전히 단절)
2. 3. 커밋 프로토콜
원자성을 달성하기 위해 트랜잭션 T를 수행하고 있는 모든 노드는 각 노드에서 커밋 되거나 중단되어야 한다. 이를 위해 T의 트랜잭션 조정자는 커밋 프로토콜을 실행한다.
2.3.1. 2단계 커밋(two-phase commit protocol - 2PC)
가장 단순하고 널리 사용되는 커밋 프로토콜은 2PC이다. 2PC를 설명하기 위해 트랜잭션 T가 노드 Ni에서 시작되었고, 트랜잭션 조정자는 Ci라고 가정한다. 2PC의 성공 플로우는 다음과 같다.
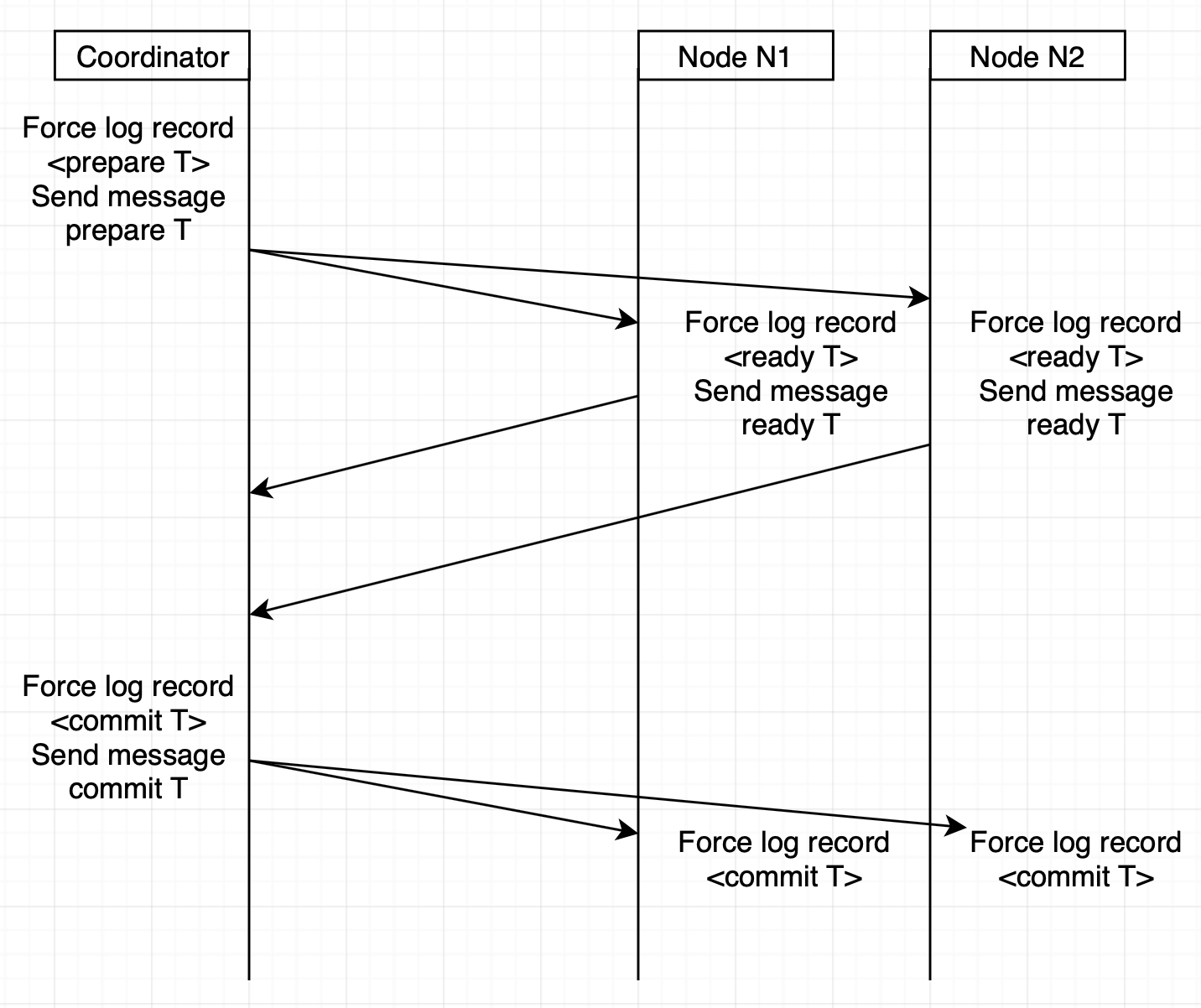
위 과정에서 만약 prepare T 메시지를 받은 노드가 커밋을 하지 않는다면
coordinator는 모든 노드로부터 commit T 메시지를 받았거나 한 개 이상의 abort T 메시지를 받았다면 트랜잭션 T를 커밋 할지 중단할지를 결정할 수 있다. 결정에 따라 로그에
2.3.1.1. 실패 처리
2PC 프로토콜은 실패 종류에 따라 다음과 같이 대처한다.
- 트랜잭션 처리에 참여한 노드의 실패
- 노드가 ready T 메시지를 보내기 전에 실패를 발견하면 노드가 abort T 메시지를 보낸 것으로 간주한다.
- coordinator가 ready T 메시지를 수신할 후 그 노드가 실패했다면, coordinator는 노드의 실패를 무시한다.
- 실패한 노드는 복구된 후에 실패할 당시의 트랜잭션 최종 결과를 알아내기 위해 자신의 로그를 검사한다. 그 후 로그에 따라 다음과 같이 행동한다.
- 로그가
레코드를 포함한다 → 노드는 redo를 실행한다. - 로그가
레코드를 포함한다 → 노드는 undo를 실행한다. - 로그가
레코드를 포함하고 있다 → coordinator에게 최종 결과를 물어본다. - 이때 coordinator가 살아있다면 노드에게 트랜잭션의 최종 결과를 알린다
- 최종 결과가 커밋이면 redo 실행
- 최종 결과가 중단이면 undo 실행
- 이때 coordinator에 장애가 발생했다면 다음 플로우를 따른다.
- 시스템의 모든 노드에게 querystatus T 메시지를 전송한다.
- 메시지를 수신한 노드는 자신이 해당 트랜잭션(T)에 참여했는지 확인한다
- 참여했다면 T가 commit 되었는지 abort 되었는지 문의한 노드에게 알린다.
- 만약 어떠한 노드도 결과를 알지 못한다면 문의한 노드는 필요한 정보를 수집할 때까지 결정을 미룬다. 즉, 필요한 정보를 가진 노드가 정상화될 때까지 주기적으로 querystatus T 메시지를 보낸다(적어도 coordinator가 존재하는 노드는 필요한 정보를 가지고 있기 때문에).
- 이때 coordinator가 살아있다면 노드에게 트랜잭션의 최종 결과를 알린다
- 로그가
- 실패한 노드는 복구된 후에 실패할 당시의 트랜잭션 최종 결과를 알아내기 위해 자신의 로그를 검사한다. 그 후 로그에 따라 다음과 같이 행동한다.
- 노드에 abort, commit, ready 레코드가 모두 없다면, 해당 노드는 preapare T 메시지에 응답하기 전에 실패했음을 의미한다. 노드가 실패했으므로 undo를 실행한다.
- coordinator의 실패: 다른 노드에 있는 로그를 통해 트랜잭션의 최종 결과를 다음과 같이 결정해야 한다.
- 정상 동작하는 노드가 로그에
-
를 가지고 있다면 트랜잭션은 커밋 된다 -
를 가지고 있다면 트랜잭션은 중단 돼야 한다 -
를 가지고 있지 않다면 노드는 coordinator에게 ready T 메시지를 전송할 수 없다. 때문에 coordinator는 트랜잭션을 커밋 할지 결정할 수 없다. 하지만 coordinator는 트랜잭션을 abort 할 수는 있다. 이 때, coordinator가 복구될 때까지 기다리기보단 트랜잭션을 중단하는 것이 더 바람직하다.
-
- 만약 위 경우에 모두 해당하지 않는다면, 살아있는 모든 노드는
레코드를 로그에 가지고 있어야만 하고, 혹은 는 가지고 있지 않아야 한다. 이 상황에서 노드가 abort 또는 commit에 대한 로그를 가지고 있지 않고 coordinator 또한 실패했기 때문에 트랜잭션의 최종 커밋 여부를 결정할 수 없다. 만약 정상 작동하는 노드가 또는 레코드를 로그에 가지고 있다면 위의 "정상 동작하는 어떤 노드가 로그에…"로 시작하는 복구 절차를 수행한다. 다만, coordinator가 복구될 때까지 기다렸다가 coordinator가 정상 동작하면 그 때 해당 복구 절차를 수행한다 - 트랜잭션의 결과가 최종 결정되지 않은 상황에선 해당 트랜잭션과 관련된 연산 자원을 계속 유지해야 한다. 이때, coordinator 복구까지 걸리는 시간을 알기 어렵고 뒤에 리소스를 기다리는 다른 트랜잭션이 존재할 수 있다. 이렇게 coordinator 복구까지 트랜잭션이 중단되는 문제를 블로킹 문제(blocking problem)이라 한다.
- 정상 동작하는 노드가 로그에
- 네트워크 분할
- coordinator와 노드들이 같은 분할에 존재한다면 문제가 발생하지 않는다
- coordinator와 일부 노드들이 서로 다른 분할에 존재한다면
- coordinator가 존재하지 않는 분할의 노드들은 coordinator 실패로 간주해 상황을 처리한다
- coordinator가 존재하는 분할에 있는 노드들은 다른 노드들이 실패한 것으로 간주해 상황을 처리한다.
- 결국 coordinator에 장애가 발생했을 때 블로킹 문제가 발생한다는 점이 가 가장 큰 문제이다.
2.3.1.2. 커밋 도중에 블로킹 문제를 피하는 방법
2PC의 블로킹 문제는 시스템에 심각한 악영향을 끼칠 수 있다. 트랜잭션이 자주 접근하는 데이터에 대한 잠금을 가진 상태에서 coordinator의 실패로 트랜잭션이 중단되었다면, 해당 잠금과 충돌하는 다른 트랜잭션의 실행을 막기 때문이다.
만약 과반수의 노드가 정상 동작하고 있고 서로 통신할 수 있다면, 2PC의 커밋 결정 단계에 여러 노드를 참여시켜서 블로킹 문제를 해결할 수 있다. 이는 분산 컨센서스 문제(distributed consensus problem)를 기반으로 한다. 분산 컨센서스 문제는 n 개의 노드가 어떤 트랜잭션의 커밋 여부를 결정한다. 모든 노드는 결정을 위한 정보를 가지고 있고, 각 노드는 결정(트랜잭션 커밋 여부)을 위해 투표한다. 컨센서스를 위한 과정 중에는 장애 발생 여부와 관련 없이 모든 노드가 결정에 대해 같은 최종 결과를 공유한다. 컨센서스 문제는 노드가 과반수 이상 정상 동작한다면 중단되지 않는다.
이제 분산 컨센서스 문제를 활용한 블로킹 문제를 피하는 시나리오에 대해 살펴보자.
- 트랜잭션 처리에 참여하고 있는 모든 노드에 커밋 또는 중단 여부를 알리기 전에 coordinator가 실패하는 경우
- 새로운 coordinator를 선택한다.
- 새로운 coordinator는 실패한 기존 coordinator에 의해 결정된 사항이 있는지를 확인한다.
- 있다면 2PC에 참여한 노드들에게 알린다.
- 없다면 참여 노드들에게 커밋 할지, 중단할지를 다시 물어본다.
- 참여 노드가 응답이 없으면 coordinator는 abort를 선택한다.
- 새로운 coordinator는 자신이 기존 coordinator인 것 처럼 행동한다.
- 분산 컨센서스 프로토콜이 결론에 도달하지 못하는 경우
- 노드가 실패해서 과반수를 유지하지 못하면 분산 컨센서스 프로토콜은 실패한다. 또 한, 커밋 또는 중단 두 선택지 모두 과반수 득표에 실패하면 결론에 도달하지 못한다.
- 이 경우 새로운 coordinator가 프로토콜을 다시 시작해야 한다.
만약 네트워크 분할이 발생하면, 과반수 노드 집합으로부터 단절되었던 한 노드는 분산 컨센서스 프로토콜이 도달한 결론에 대해 모를 수 있다. 때문에 해당 노드에서 실행 중인 트랜잭션은 중단될 수 있다.
2.3.2 영속 메시지(persistent message)
위에서 설명한 2PC(Two-Phase Commit)의 경우 다음과 같이 자율성을 제한한다.
- 모든 노드는 coordinator가 트랜잭션 최종 결과를 결정하게 위임한다
- coordinator가 결정할 때까지 대기한다
- 갱신된 데이터에 대해선 잠금을 유지한다
이런 자율성 제한은 노드를 얼마나 걸릴지 모르는 시간 동안 불필요하게 대기시킨다.
영속 메시지는 트랜잭션을 커밋 하기로 결정했다면 수신자에게 정확히 한 번 전송되는 것을 보장하는 메시지이다. 만약 트랜잭션이 중단된다면 전송하지 않는 것을 보장한다. 이런 메시지 처리는 노드의 실패와 무관하게 동작한다. 이에 반해 일반 메시지는 손실되거나 특정 상황에서 여러 번 전송될 수도 있다.
예외가 발생하는 조건은 애플리케이션에 따라 다르기 때문에 데이터베이스 시스템 단에서 오류를 자동으로 다루는 것은 불가능하다. 영속 메시지를 전송하고 받는 애플리케이션은 반드시 예외 처리를 직접 구현하고 데이터베이스 시스템을 일관된 상태로 복구해야 한다.
영속 메시지가 진행되는 플로우는 다음과 같다.
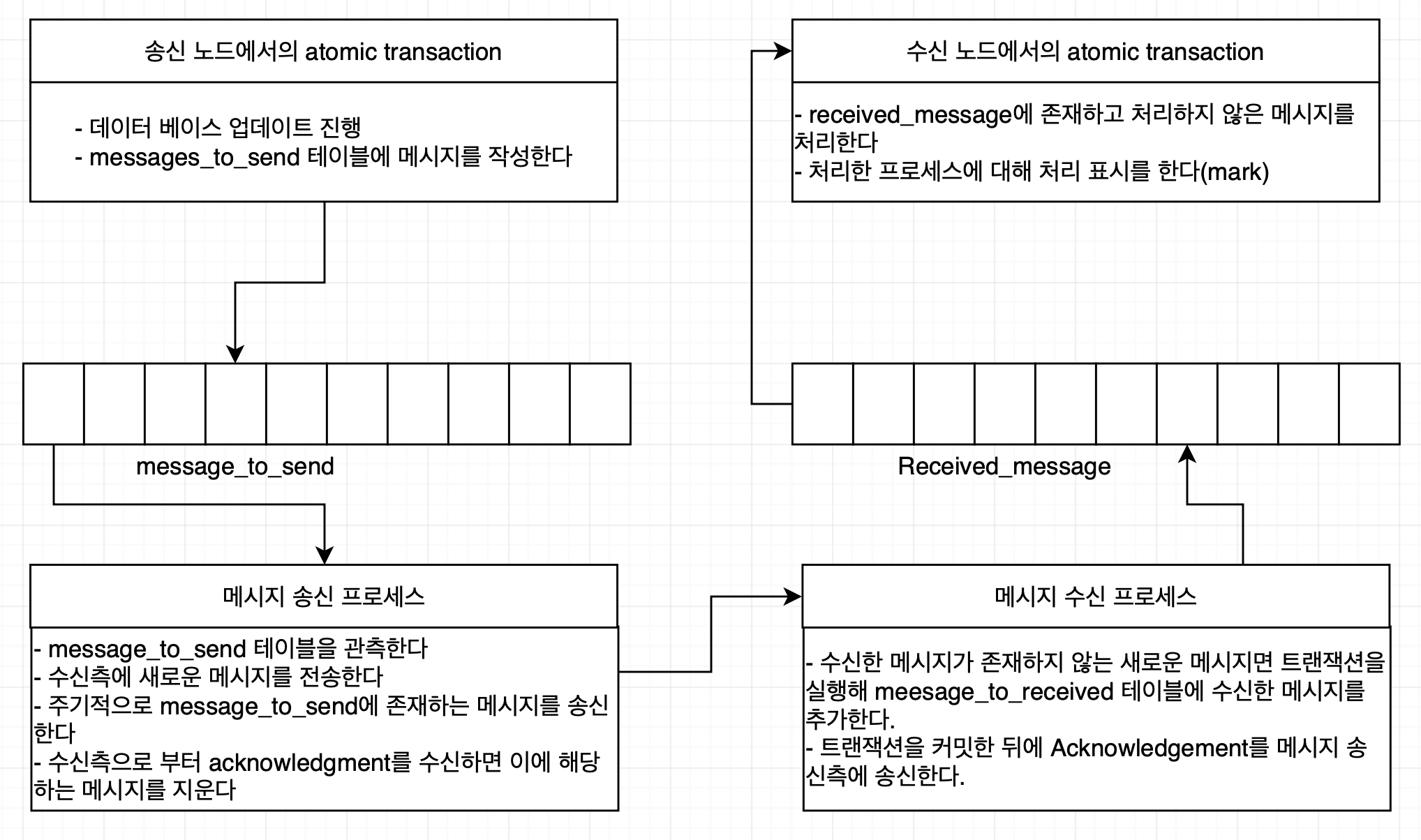 이 플로우 각 절차의 세부 사항은 다음과 같다.
이 플로우 각 절차의 세부 사항은 다음과 같다.
- 송신 노드에서의 atomic transaction
- message_to_send 테이블에 메시지를 작성한다
- 작성된 메시지는 고유한 식별자를 할당받는다.
- message_to_send 테이블에 메시지를 작성한다
- 메시지 송신 프로세스
- 수신 측에 새로운 메시지를 전송한다
- 메시지 송신 프로세스는 메시지 추가 트랜잭션이 커밋 한 이후에 해당하는 메시지만 고려한다. 만약 메시지를 message_to_send 테이블에 추가하는 트랜잭션이 중단되면, 해당 메시지를 테이블에서 삭제한다.
- 주기적으로 message_to_send에 존재하는 메시지를 송신한다
- 임시적인 네트워크 실패에 대해선 메시지 송신을 보장한다.
- 만약 영구적인 실패 상황이라면, 시스템은 일정 시간 후에 메시지를 전송할 수 없다고 판단한다. 이때는 애플리케이션에 정의된 오류 처리 코드를 실행해 실패를 해결한다.
- 수신 측에 새로운 메시지를 전송한다
- 메시지 수신 프로세스
- 수신한 메시지가 존재하지 않는 새로운 메시지면 트랜잭션을 실행해 messagee_to_receied 테이블에 수신한 메시지를 추가한다
- 고유한 메시지 식별자를 통해 기존에 수신한 메시지인지 확인한다.
- 추가하는 메시지는 메시지가 처리되었는지를 나타내는 속성값을 가지고 초깃값은 false이다.
- 수신한 메시지가 존재하지 않는 새로운 메시지면 트랜잭션을 실행해 messagee_to_receied 테이블에 수신한 메시지를 추가한다
- 수신 노드에서의 atomic transaction
- received_message에 존재하고 처리하지 않은 메시지를 처리한다.
- 메시지에 적힌 행동을 수행한다.
- 처리한 프로세스에 대해 처리 표시를 한다
- 처리 완료했음을 알리는 flag를 true 표시로 바꾼다.
- received_message에 존재하고 처리하지 않은 메시지를 처리한다.
영속 메시지는 흔하지는 않지만 메시지가 임의의 시간 동안 전송이 지연되는 현상이 발생한다. 이때, 네트워크가 지연되어 메시지 A에 대해 수신 측은 Acknowledgement를 송신했지만 송신 측은 받지 못했고, 송신 측은 다시 메시지 A를 보낸다고 해보자. 그 사이 수신 측은 메시지 A를 실행 완료하고 삭제했다면 수신 측은 메시지 A에 대해 중복 여부를 판단할 수 없어 같은 행위를 다시 실행한다. 이를 방지하기 위해 메시지를 삭제하지 않는다면 received_messages 테이블이 무제한으로 커진다. 이에 대한 타협으로 메시지마다 타임스탬프를 기록해 일정 기간이 지나면 만료처리해서 테이블에서 삭제하면 된다.