- 서버를 진단하기 위해서 서버로부터 획득할 수 있는 정보에는 다음과 같은 것들이 있다.
- 요약: 단위 시간 정보의 합계나 평균을 보여준다. 평균이기에 대략적인 상태만 파악할 수 있다.
- 사용 명령어: vmstat, sar
- 이벤트 기록: 패킷, 시스템 콜
- 스냅샷: 순간의 상태를 기록한다. 현재 문제가 발생하고 있지 않은지, 발생한다면 원인 조사에 사용한다.
- 사용 명어: top
- 서버 진단 시에는 로그, 요약 정보로 각 리소스의 대략적인 상태를 파악하고, 스냅샷으로 원인을 파악한다.
- 요약: 단위 시간 정보의 합계나 평균을 보여준다. 평균이기에 대략적인 상태만 파악할 수 있다.
1. 서버를 진단하는 방법 - USE(Utilization, Saturation, Error)
- USE 방법론은 다음과 같은 세 가지 관점으로 서버를 진단한다.
- Utilization: 자원을 얼마나 사용했나
- Saturation: 얼마나 많은 부하가 몰렸나
- Errorr: 에러가 발생했나.
- USE 방법론의 플로우는 다음과 같다.
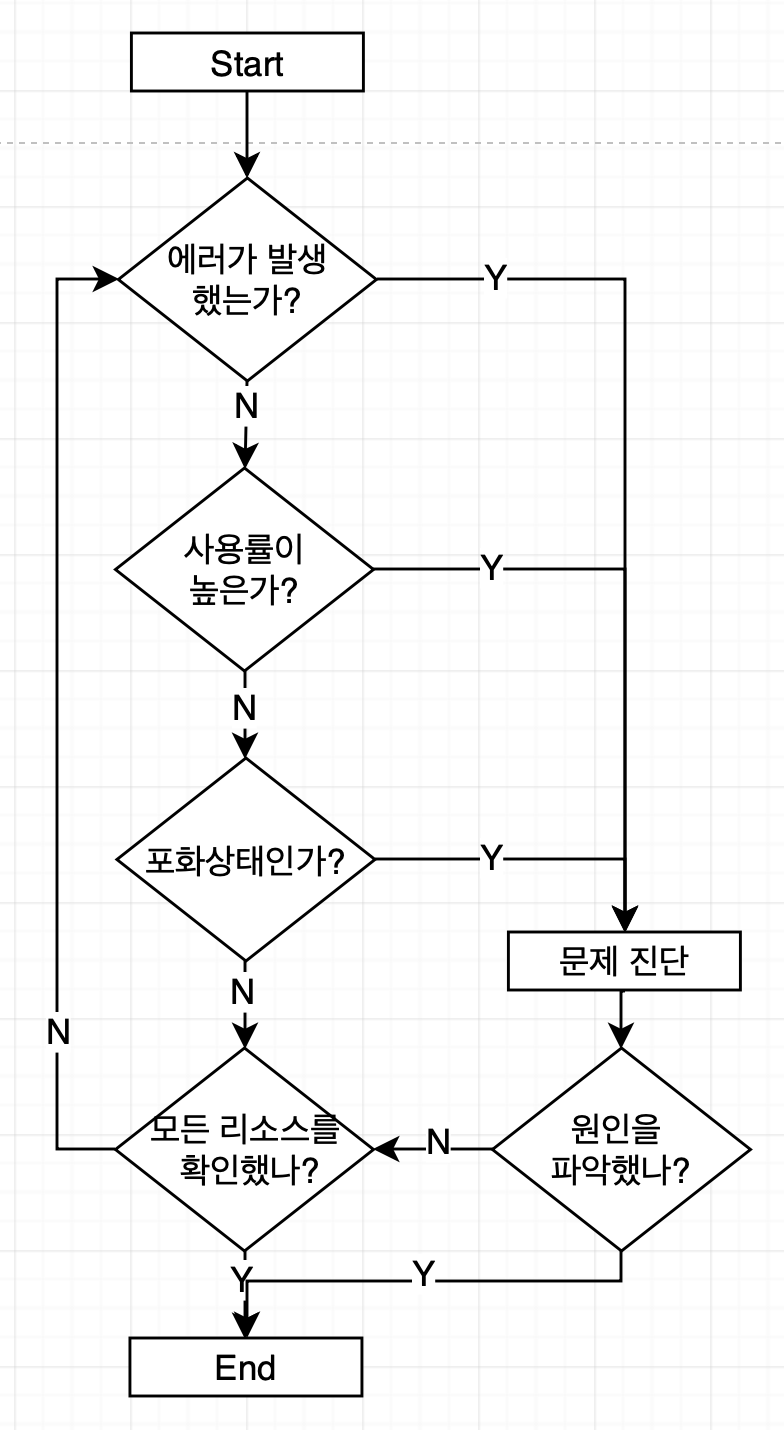
- 각 단계에서 확인해야 하는 것들은 다음과 같다.
1.1 에러가 발생했는가?
- 로그를 확인해 본다. 시스템 로그는 /var/log/syslog, cron, dmesg 등으로 확인한다. 애플리케이션 로그를 확인할 때는 직전 배포와 연관이 있는지, 특정 사용자, 특정 시간, 특정 조건과 관련이 있는지를 확인해 본다. 이를 통해 맥락을 파악해서 근본적인 원인을 찾는다.
1.2 사용률이 높은가?
- 서버 장비의 경우 다음과 같은 지표를 확인한다
- CPU 사용률:
- 특정 기간 동안 CPU가 작업을 수행한 전체 시간을 백분율로 측정한 것이다. 이론적으로 사용률이 높아도 성능이 급격히 떨어지지는 않는다. 커널에서 우선순위에 따라 프로세스나 스레드를 선점하고 시분할 하기 때문이다. 다만 CPU 사용률이 100% 라면 포화상태이고 곧 대기할 프로세스가 생긴다는 의미이다. 최대 70%를 넘지 않게 하는 것이 좋다.
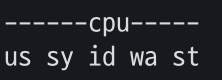
- vmstat CLI를 통해 CPU의 us(user) time과 sy(system, kernel) time 비율을 확인한다. 여기서 유저 시간이 평소보다 높다면, CPU 사용률이 높은 프로세스나 스레드를 찾아봐야 한다. 만약 모든 스레드의 CPU 사용률이 높다면 scale up을 고려해야 한다. 만약 특정 스레드만 CPU 사용률이 높다면 수행 중인 task를 분석하고 로직을 개선해야 한다.
- CPU 사용률:
- 메모리 가용 용량:
- 새로운 프로세스나 기존 프로세스에 할당할 수 있는 메모리 양이다. free -wh 커맨로 나오는 메모리 지표의 available 부분에서 확인할 수 있다. 가용 용량이 모자란다면 새로운 프로세스 할당 시 page replacement가 발생한다. 이로 인해 swapping 빈도가 증가해서 속도가 느려질 수 있다.

- 새로운 프로세스나 기존 프로세스에 할당할 수 있는 메모리 양이다. free -wh 커맨로 나오는 메모리 지표의 available 부분에서 확인할 수 있다. 가용 용량이 모자란다면 새로운 프로세스 할당 시 page replacement가 발생한다. 이로 인해 swapping 빈도가 증가해서 속도가 느려질 수 있다.
- 디스크 사용률:
- 부족하면 증설, 마운트를 하고 불필요한 파일은 지운다.
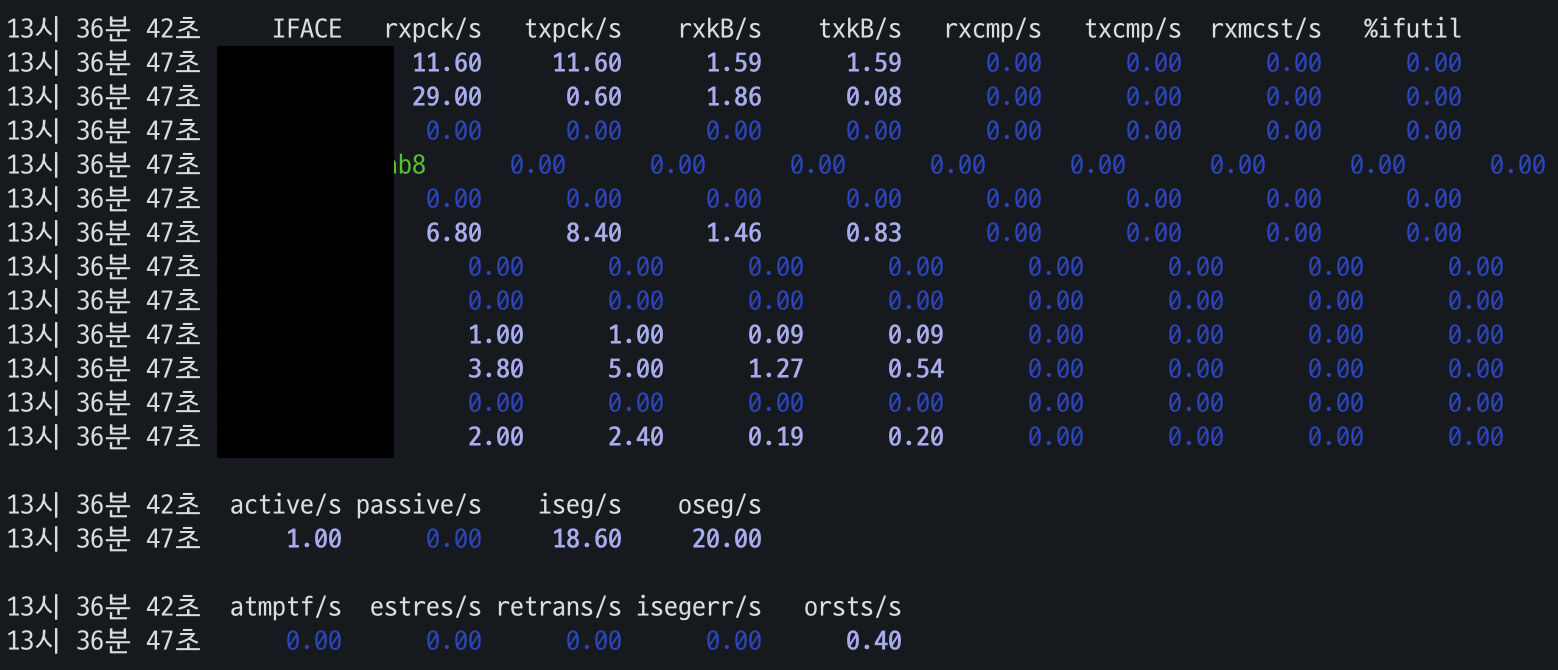
- iostat -xt 커맨드를 커널에서 취득한 디스크 사용률을 알 수 있다. 확인해볼 지표는 다음과 같다.
- r/s: read 요청
- w/s: write 요청
- rkB/s: read kB
- wkB/s: write kB

- 네트워크 사용률:
- 주고받은 패킷 양을 의미한다.
- 다음 지표 중
- active/s: 서버에서 다른 외부 장비로 연결한 횟수. 이 값이 증가했다면 서버에 악성코드가 있는지, 의도하지 않은 cron job이 있는지를 확인해야 한다.
- passive/s: 서버에 새로 접근한 클라이언트 수
1.3 부하
- 부하는 처리를 실행하려고 해도 실행할 수 없어서 대기하고 있는 프로세스 수이다.
- 부하를 해결할 수 있는 부분과 방법은 다음과 같다.
- CPU:
- 포화상태인지를 판단하기 위해 평균 부하가 코어 수보다 높은지를 확인한다. 평균 부하는 uptime 커맨드를 통해 확인할 수 있다.

- top 커맨드를 통해 프로세스 상태가 R 또는 D이면서 CPU 사용률이 높은 프로세스의 원인을 파악하면 된다.
- 포화상태인지를 판단하기 위해 평균 부하가 코어 수보다 높은지를 확인한다. 평균 부하는 uptime 커맨드를 통해 확인할 수 있다.
- Memory:
- CPU 사용량이 낮음에도 가용 가능한 메모리나 낮다면 memory swap이 발생하는지를 체크해야 한다.
- 이 경우 top 명령어에서 RES가 큰 프로세스가 없는지 확인해야 한다.
- RES: 실제 물리 메모리 영역 크기
- VIRT: 프로세스가 확보한 가상 메모리 영역의 크기
- 만약 메모리 swap in, out이 많이 발생한다면 메모리가 부족하다는 의미이다. 따라서 메모리를 늘리거나, SSD를 늘리거나, 메모리 지역성 향상, 메모리 I/O 양을 줄이는 등의 성능 개선을 해야 한다. Memory leak이 발생했는지도 확인해 보고 그렇다면 문제 되는 로직을 개선해야 한다.
- 이 경우 top 명령어에서 RES가 큰 프로세스가 없는지 확인해야 한다.
- CPU 사용량이 낮음에도 가용 가능한 메모리나 낮다면 memory swap이 발생하는지를 체크해야 한다.
- Network:
- 위 네트워크 사용률 확인에서 사용한 커맨드로 나온 지표 중 하나인 재전송 비율(retrans/s)이 0.5%보다 높은지 확인해 봐야 한다.
- 패킷 재전송은 패킷 손실을 방지하기 위해 발생한다. 애플리케이션 오작동, 라우터의 과부화 트래픽, 일시적인 서비스 정지 등으로 인해 패킷이 손실될 수 있다. 이 경우 리눅스는 최대 15회 이상 재전송해서 그 안에 ACK를 받으면 정지한다.
- 위 네트워크 사용률 확인에서 사용한 커맨드로 나온 지표 중 하나인 재전송 비율(retrans/s)이 0.5%보다 높은지 확인해 봐야 한다.
- CPU:
2. RED(Rate, Error, Duration) 방법론
- 위에서 설명한 RSE 방법론은 한 대의 서버를 진단하기에는 괜찮지만 여러 서버들을 운영할 때 부합하지 않는 부분도 존재한다. 따라서 여러 서버를 운영해야 한다면 RED 방법론도 같이 사용하는 것이 좋다. RED 방법론은 다음과 같은 것들을 체크한다.
- Rate: 초당 처리한 요청 수
- Error: 처리에 실패해 오류가 발생한 요청 수
- Duration: 요청을 처리하는데 걸린 시간
- USE, RED 방법론을 종합적으로 사용했을 때, 다음과 같은 모니터링 지표들을 살펴봐야 한다.
