1. 실시간 데이터 시스템 구조
실시간 데이터 시스템에 대해 이해하기 위해, 우선 배치 시스템 구조를 살펴보자.
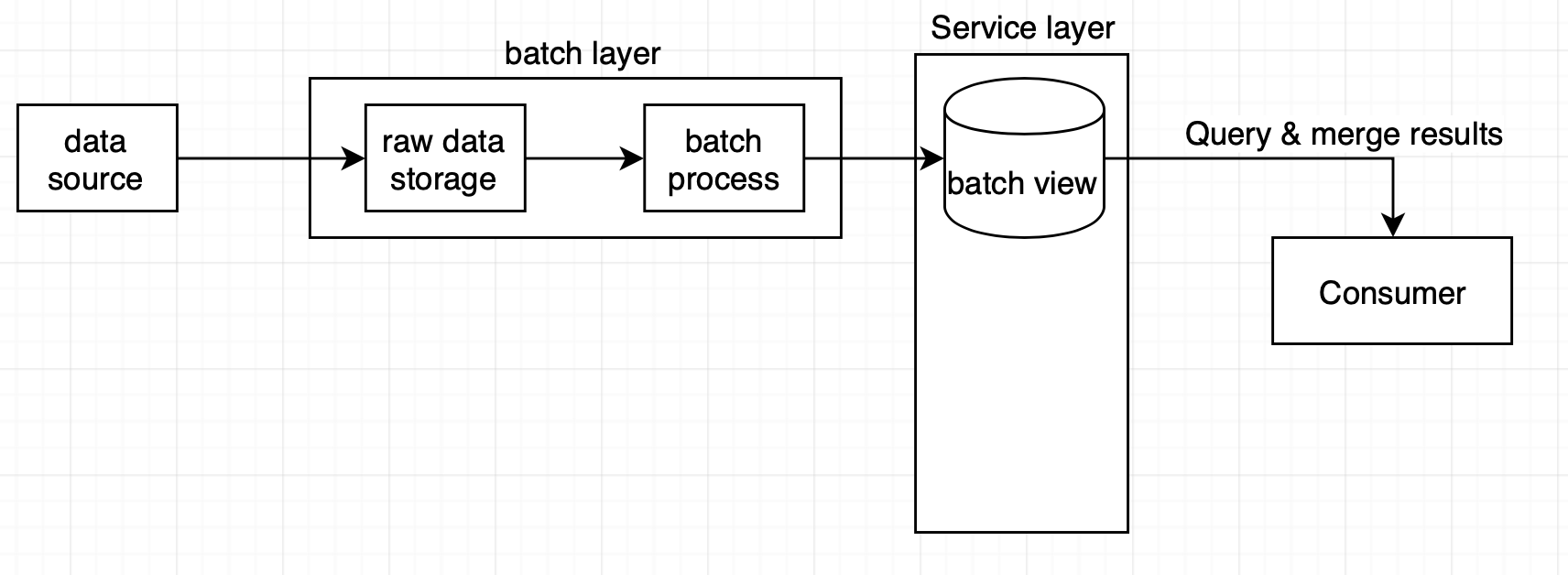
- raw data storage는 배치 처리가 필요한 데이터를 저장하는 저장소이다.
- batch process는 저장된 데이터를 이용해 시간별, 일별로 통계 계산과 데이터 가공 작업을 수행하고 consumer가 이를 소비할 수 있게 batch view에 저장한다.
위와 같은 구조는 데이터가 실시간 스트리밍 방식으로, 연속적으로 생성되는 환경에 대응하지 못한다. 배치 프로세스는 특정 시간 단위를 주기로 데이터를 처리하기 때문이다. 따라서 실시간 데이터를 모아서 배치 프로세스로 보내기 위해 다음과 같은 구조가 추가된다.
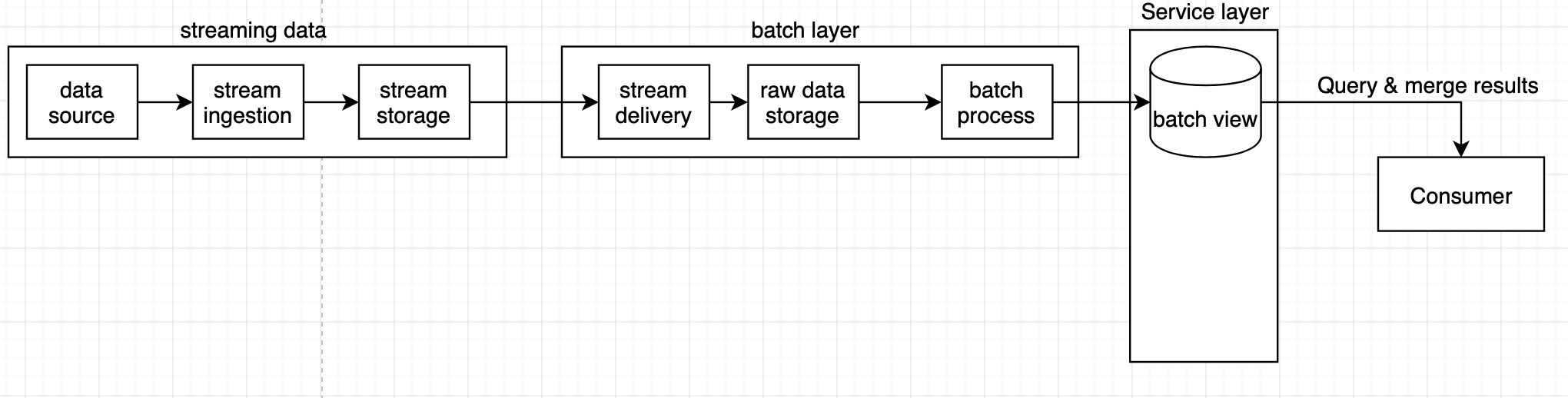
- stream storage: 실시간 데이터를 모았다가 배치 프로세스에 보내기 위해 사용하는 버퍼
- stream ingestion: 스트림 데이터를 stream storage에 넣기 위해 사용
- stream delivery: stream storage에 있는 데이터를 다른 곳으로 옮기는 역할
여기서, 데이터를 배치 처리가 아닌, 실시간으로 데이터를 읽어서 처리하고 싶다면, 다음과 같은 프로세스를 추가해야 한다. 이렇게 실시간으로 데이터를 처리하는 프로세스를 배치 레이어와 대응해서 스피드 레이어라고 부른다.
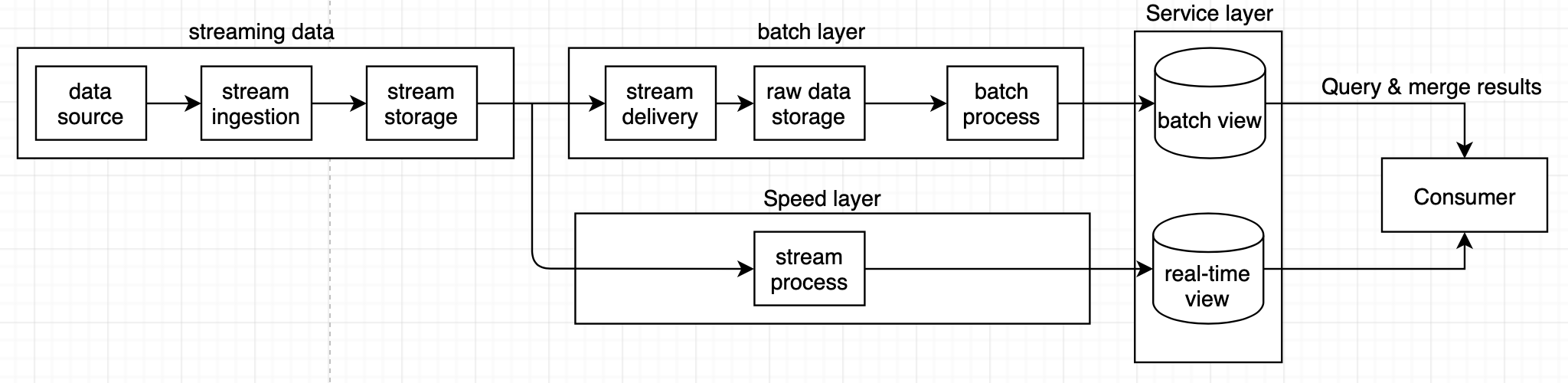
종합적으로 살펴보면 실시간 데이터 처리 시스템은 다음과 같은 세 가지 구조로 나누어진다.
- batch layer: 스트리밍 데이터를 한 번에 모아서 처리하는 레이어
- speed layer: 실시간 처리를 담당한다
- service layer는 배치 레이어와 스피드 레이어의 처리 결과를 제공한다
이러한 3개의 레이어로 나누어진 아키텍처를 람다 아키텍처라고 한다.
람다 아키텍처를 조금 더 거시적으로 보면, 실시간 데이터 분석 시스템은 다음과 같은 구조를 갖는다.

- stream ingestion: stream storage에 데이터를 넣는 역할
- stream storage: 데이터 버퍼링 담당 (입력 순서 보장, 재처리, 일정 기간 저장 가능)
- stream process: 데이터를 변경하는 프로세스
- data sink: 데이터를 소비하는 주체(data lake, data warehouse)
AWS 서비스 중 Amazon kinesis data streams(이하 kinesis)와 Amazon Managed Streaming for Kafka(MSK)는 stream sotrage 역할을 한다.
2. kinesis와 MSK의 3가지 특징
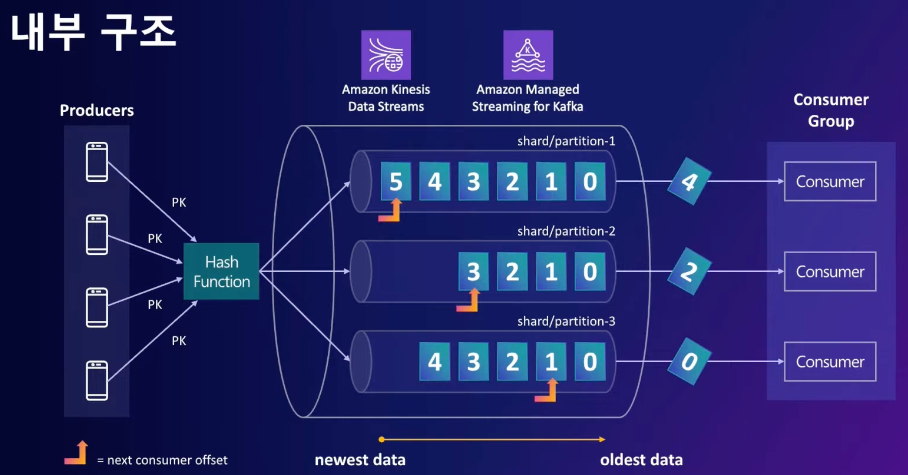
2.1 분산 큐
- 데이터가 입력된 순서대로 처리되게 순서를 보장해 준다
- 데이터를 여러 개로 나눠서 처리할 수 있게 만들어졌다
- kinesis와 MSK의 큐는 scale-out을 사용하기에 분산이라는 특징을 가진다. 이 때문에 producer가 많아져도 데이터를 감당할 수 있다.
- 이러한 큐를 kinesis에선 샤드, MSK와 카프카에선 파티션이라 한다.
- 각 큐는 식별을 위해 번호를 붙인다.
- 데이터를 여러 큐에 분배를 위해 해시 함수를 사용한다. producer에서 파티션 키를 데이터랑 같이 보내면, 이 키를 기준으로 분배한다.
2.2 스트림 스토리지
- 데이터를 저장하기 위해 메모리가 아닌, 비휘발성 저장소를 사용한다
- consumer가 데이터를 읽었다고 해서, 그 데이터를 삭제하지 않고 남겨둔다. 대신 다음에 읽을 데이터의 위치를 별도로 표시한다. 이 때문에 consumer가 같은 데이터를 여러 번 읽을 수 있다.
- 데이터를 얼마나 오래 보관할 것인지를 설정한다. 이를 retention이라 한다. 이 기간이 지나면 오래된 순서대로 자동 삭제한다.
3. 스트림 스토리지를 사용했을 때의 이점
- producer와 consumer 사이에 스트림 스토리지가 존재하기에 producer와 consumer를 디커플링시킬 수 있다.
- 이를 통해 producer와 consumer의 데이터 생산, 소비 속도를 서로 다르게 가져갈 수 있다.
- 여러 producer가 생산한 데이터를 하나의 consumer가 사용하기 위해 여러 개의 producer를 consumer가 연결할 필요가 없다.
- 데이터의 입력 순서가 보장된다. 단, 샤드와 샤드 간의 데이터 순서는 보장이 안된다. 즉, 전체 순서 보장이 아니라 단일 샤드 내에서만 순서가 보장된다.
- consumer가 서로 다른 샤드에 있는 데이터를 동시에 읽을 수 있다.
- 파티션키를 기준으로 서로 다른 샤드에 저장되기 때문에 consumer들은 grouping된 데이터를 동시에 소비할 수 있다. 이런 데이터 처리를 streaming map reduce라고 한다.
4. MSK와 kinesis 차이점
MSK는 카프카를 AWS에서 managed service 형태로 제공하는 것이기에 구조가 카프카와 동일한다.
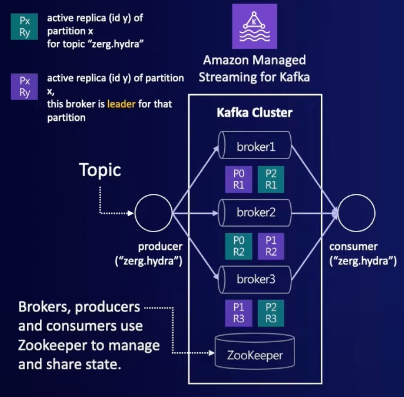
- broker라고 하는 서버들이 클러스터링 되어 있다.
- broker는 웹 서버 같은 것이다
- 브로커들은 주키퍼에 의해 관리된다
- 데이터를 주고받기 위해 논리적으로 토픽을 생성한다. producer는 토픽에 따라 데이터를 넣어준다, 그러면 데이터는 파티션 키를 기준으로 여러 파티션에 나눠서 저장된다.
- consumer는 토픽 별로 데이터를 읽는다.
- 파티션 별로 저장된 데이터의 유실을 막기 위해 파티션들을 여러 브로커에 복제한다.
- 주키퍼는 어떤 파티선이 primary 이고, 어떤 것이 replica 인지 관리한다.
- 토픽의 파티션 수를 증가시킬 수는 있지만, 감소시킬 수는 없다
- 성능을 올리기 위해 브로커를 추가하는 클러스터 프로비저닝 모델을 사용한다.
kinesis 구조는 다음과 같다.
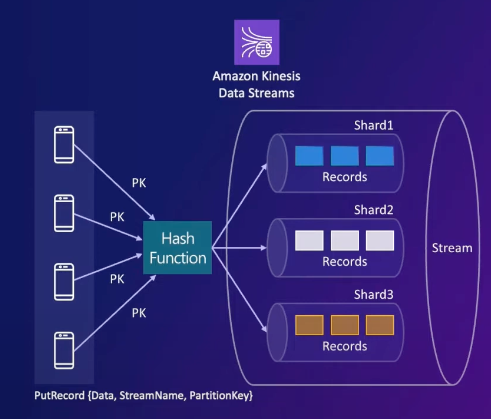
- 카프카의 파티션과 대응되는 stream, 파티션과 대응되는 샤드를 가진다.
- 데이터를 샤드에 넣어두면 파티션 키에 따라 자동으로 샤드에 분배되고 저장된다.
- 위와 같은 이유로 kinesis가 MSK에 비해 추상화 레벨이 높다.
- 샤드의 수를 증가시키거나 감소시킬 수 있다.
- 성능을 올리기 위해 초당 몇 번의 데이터를 쓰고 읽을지를 변경해서 성능을 올리는 throughput 프로비저닝 모델을 사용한다.
출처 - 데이터 분석 실시간으로 처리하기: Kinesis Data Streams vs MSK