구조적 API를 사용하면 비정형, 반정형, 정형 데이터를 모두 처리할 수 있다. 구조적 API에는 다음과 같은 세 가지 분산 컬렉션 API가 있다.
- Dataset
- DataFrame
- SQL 테이블과 뷰
구조적 API를 사용하면 배치 작업을 간단히 스트리밍 작업으로 변환할 수 있다.
스파크는 트랜스포메이션 처리 과정을 정의하는 분산 프로그래밍 모델이다. 트랜스포메이션은 DAG로 표현되는 명령을 만들고 액션은 하나의 잡을 클러스터에서 실행하기 위해 stage와 task로 나누고 DAG 처리 프로세스를 실행한다. DataFrame과 DataSet은 트랜스포메이션과 액션으로 다루는 논리적 구조이다. 새로운 DataFrame이나 DataSet을 만들기 위해선 트랜스포메이션을 호출해야 한다. 연산을 시작하거나 사용한 언어에 맞는 데이터 타입으로 변환하려면 액션을 호출해야 한다.
1. DataFrame과 Dataset
- 공통점
- 로우와 컬럼을 가지는 분산 테이블 형태의 컬렉션이다 (RDB 테이블과 같다)
- 모든 row는 같은 데이터 타입을 가진다
- 불변이다
- 결과를 생성하기 위해 어떤 연산을 해야 하는지 정의하는 지연연산의 실행계획이다
- 로우와 컬럼을 가지는 분산 테이블 형태의 컬렉션이다 (RDB 테이블과 같다)
2. 스키마
분산 컬렉션에 저장할 컬럼명과 데이터 타입을 정의하는 방법이다. 데이터 소스에서 얻거나 직접 적의할 수 있다. 직접 정의할 때는 어느 데이터 타입이 어느 위치에 있는지 정의해야 한다.
3. 스파크의 구조적 데이터 타입 개요
스파크는 사실상 프로그래밍 언어다. 우선, 스파크는 실행 계획 수립과 처리에 사용하는 자체 데이터 타입 정보를 가지는 카탈리스트(catalyst) 엔진을 사용한다. 스파크는 각 언어에 대한 매핑 테이블을 가지고 있다. 때문에 특정 언어를 이용해 구조적 API를 사용할때, 언어 자체의 타입이 아닌 스파크 데이터 타입을 사용한다. 예컨데, 아래 코드에서 덧셈음 언어 자체의 덧셈이 아닌, 스파크의 덧셈 연산이다.
1
2
3
4
df = spark.range(500).toDF("number")
# 카탈리스트 엔진은 스파크가 지원하는 언어로 작성된 표현식을 스파크 데이터 타입으로
# 변환해 명령을 처리한다.
df.select(df["number"] + 10)
3.1 DataFrame과 DataSet 비교
DataSet은 스키마에 명시된 데이터 타입 일치 여부를 컴파일 타임에 확인하고, DataFrame은 런타임에 확인한다. Dataset은 스칼라와 자바에서만 지원한다. 파이썬과 R에서는 DataFrame을 사용할 수 있다. DataFrame은 Row 타입으로 구성된 Dataset이다. Row 타입은 스파크가 사용하는 연산에 최적화된 인메모리 포맷이다. Row 타입을 사용하면 GC와 객체 초기화 부하가 있는 JVM 데이터 타입을 사용하는 대신 최적화된 자체 데이터 포맷을 사용하기에 효율적인 연산이 가능하다.
3.2 컬럼
컬럼은 단순 데이터 타입, 복합 데이터 타입, null 값을 표현한다. 스파크는 데이터 타입의 모든 정보를 추적해서 다양한 컬럼 변환 방법을 제공한다.
3.3 로우
데이터 레코드이다. DataFrame의 레코드는 Row 타입으로 구성된다. Row는 SQL, RDD, 데이터소스에서 얻거나 만들 수 있다.
3.4 스파크 데이터 타입
스파크는 다양한 내부 데이터 타입을 가지고 있다. 스파크가 지원하는 파이썬 매핑 정보는 다음과 같다.


4. 구조적 API의 실행 과정
구조적 API 쿼리가 사용자 코드에서 실제 실행 코드로 변환되는 과정을 보자. 대략적인 진행 과정은 다음과 같다.
- DataFrame/Dataset/SQL을 이용해서 코드를 작성한다
- 정상적인 코드면 스파크가 논리적 실행 계획으로 변환한다
- 스파크는 논리적 실행 계획을 물리적 실행 계획으로 변환하고, 그 과정에서 추가적인 최적화를 할 수 있다.
- 스파크는 클러스터에서 물리적 실행 계획(RDD 처리)을 실행한다.
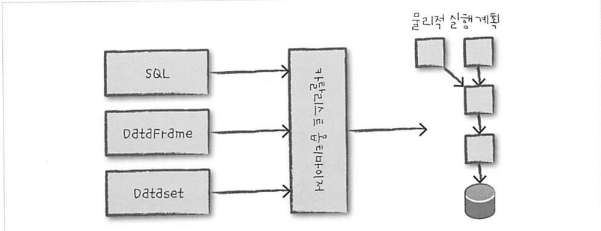
4.1 논리적 실행 계획
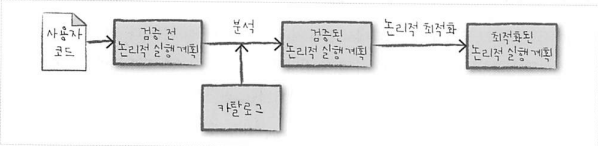
드라이버와 executor 정보를 고려하지 않고 추상적 트랜스포메이션만 표현하는 단계이다. 위 그림 의 각 단계는 다음과 같은 역할을 한다.
- 검증 전 논리적 실행계획(unresolved logical plan): 사용자의 다양한 표현식을 최적화된 버전으로 변환한다. 코드 유효성, 테이블과 컬럼 존재만 판단한다. 실행 계획을 검증하지 않은 상태
- 필요한 테이블이나컬럼이 카탈로그에 없으면, 검증 전 논리적 실행계획은 만들어지지 않는다.
- 분석기: 컬럼, 테이블을 검증하기 위해 카탈로그, 모든 테이블 저장소, DataFrame 정보를 활용한다
- 논리적 최적화: 카탈리스트 옵티마이저가 predicate pushing down이나 선택절 구문을 이용해 논리적 실행 계획을 최적화한다. 카탈리스 옵티마이저는 이러한 최적화 규칙의 모음이다.
4.2 물리적 실행 계획
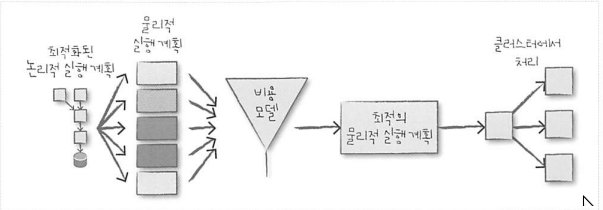
물리적 실행 계획은 스파크 실행 계획이라고도 불리며 논리적 실행 계획을 클러스터 환경에서 실행하는 방법을 정의한다. 위 그림처럼 다양한 물리적 실행 계획에 대한 비용 모델을 만들고, 비용을 비교한다. 그 후, RDD와 트랜스포메이션으로 변환한다.
4.3 실행
스파크는 물리적 실행 계획을 선정하고 RDD를 대상으로 모든 코드를 실행한다. 스파크는 런타임에 전체 태스크나 스테이지를 제거할 수 있는 자바 바이트 코드를 생성해 추가적인 최적화를 수행한다. 그 후 처리 결과를 사용자에게 반환한다.
출처 - 스파크 완벽 가이드