쿠버네티스는 대부분의 리소스를 ‘오브젝트’라는 형태로 관리한다. 대표적인 오브젝트로는 pod, replicaset이 있다. 오브젝트 목록은 터미널에서 ‘kubectl api-resources’ 커멘드로 확인 가능하다.
쿠버네티스는 대부분의 리소스를 YAML 파일로 관리할 수 있다.
쿠버네티스는 여러 개의 컴포넌트로 구성돼 있다. 쿠버네티스 노드는 마스터 노드, 워커 노드로 나뉜다. 마스터 노드는 클러스터를 관리한다. 워커 노드에는 애플리케이션 컨테이너가 생성된다. 노드 안에는 다양한 컴포넌트 들이 존재하는데, 대표적인 컴포넌트들은 다음과 같다.
- 마스터 노드: API 서버, 컨트롤러 맨터, 스케줄러, DNS 서버 등
- 모든 노드:
- 오버레이 네트워크 구성용: kube-proxy, 네트워크 플러그인(calico, fannel 등)
- 쿠버네티스 크러스터 구성용: kubelet(에이전트 노드 - 컨테이너 생성, 삭재, 마스터-워커 간 통신 담당)
1. 파드(Pod): 컨테이너를 다루는 기본 단위
Pod는 쿠버네티스에서 컨테이너 애플리케이션을 배포하기 위한 기본 단위이다. 파드는 1개 이상의 컨테이너로 구성되어 있다.
yaml 파일로 파드를 생성해보자
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion: v1 # 파일에서 저의한 오브젝트의 API 버전
kind: Pod # 리소스 종류
metadata: # 라벨, 주석 같은 리소스 부가 정보
name: my-nginx-pod
spec: # 리소스 생성을 위한 상세 정보
containers: # 실행될 컨테이너 정보
- name: my-nginx-container
image: nginx:latest
ports:
- containerPort: 80
protocol: TCP
# 실행 방법: kubectl apply -f nginx-pod.yml
# 실행 중인 파드 확인: kubectl get pods
이렇게 생성된 파드는 아직 외부에서 접근할 수 없다. 외부에서 파드 접근을 위해서는 서비스 오브젝트를 따로 생성해야 한다.
쿠버네티스가 도커 컨테이너 대신 파드를 사용하는 이유는 여러 리둑스 네임스페이스를 공유하는 여러 컨테이너들을 추상화된 집합으로 사용하기 위해서이다.
하나의 파드는 하나의 완전한 애플리케이션이다. 이 때문에 통상적으로 하나의 파드에는 하나의 컨테이너만 존재한다. 만약 애플리케이션 실행을 위해 부가 기능이 필요하다면, 파드 하나에 주 컨테이너와 부가적인 컨테이너를 같이 설정할 수 있다. 부가적인 컨테이너를 사이드카라고 부른다. 이렇게 만들어진 사이드카 컨테이너는 파드 내에 있는 다른 컨테이너와 네트워크를 공유한다.
2. 레플리카셋
위 파드 설명 처럼 YAML 파일에 파드만 정의할 경우 해당 파드는 오직 사용자에 의해 관리된다. 때문에 여러 개의 동일한 컨테이너에 대한 로드밸런싱, 장애 시 대응 등 파드에 대한 관리가 어렵다. 이런 문제를 해결하기 위해 레플리카셋이라는 오브젝트를 사용한다. 레플리카셋은 다음과 같은 역할을 한다.
- 정해진 수의 동일한 파드가 항상 실행하게 관리한다
- 노드 장애 등의 이유로 파드를 사용할 수 없다면, 다른 노드에서 파드를 다시 생성한다.
여기서, 레플리카셋의 목적은 파드를 생성하는 것이 아닌, 파드 갯수를 유지한다는 것을 주의해야한다. 레플리카셋을 생성할 때, 파드가 없으면 같이 생성되는대 이는 파드 갯수를 맞추기 위함이다.
레플리카셋은 다음과 같은 YAML 파일로 정의할 수 있다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
apiVersion: apps/v1
# replica set 정의 영역
kind: ReplicaSet
metadata:
name: replicaset-nginx
spec:
replicas: 3 # 유지할 파드 갯수, 갯수를 조정하기 위해서 기존 생성된 레플리카셋을 삭제할 필요 없다.
selector:
matchLabels:
app: my-nginx-pods-label
# 파드 정의 영역
template: # 사용할 파드에 대한 정의 영역
metadata:
name: my-nginx-pod
labels: # 라벨은 쿠버네티스 리로스를 분류할 때 사용하는 메타데이터
app: my-nginx-pods-label
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
레플리카셋의 생성/삭제는 파드의 생성/삭제에도 영향을 미치지만, 이 둘은 느슨한 연결을 유지하고 있다. 이는 라벨 셀렉터에 의해 이루어진다. 위 설정에서 레플리카셋과 파드는 같은 라벨을 공유한다. 라벨은 서로 다른 오브젝트가 서로를 찾을 때 사용한다. 때문에 라벨만 일치하다면 레플리카셋과 파드를 YAML 파일 여러개로 나눠 생성해도 레플리카셋은 해당 파드를 찾아 관리한다.
레플리카 컨트롤은 이전 버전에서 파드 갯수를 유지하는 오브젝트였다. 현재는 deprecated되었다. 레플리카셋은 레플리카 컨트롤과 달리 표현식 기반 라벨 셀렉터를 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset-nginx
spec:
replicas: 3
selector:
matchLabels:
app: our-nginx-pods-label
matchExpressions:
- key: app2
values:
- my-nginx-pods-label
- your-nginx-pods-label
operator: In # 위 두 라벨 중 하나에 맞는 파드면 모두 해당 레플리카셋이 관리한다.
template:
metadata:
name: my-nginx-pod
labels:
app: our-nginx-pods-label
app2: my-nginx-pods-label
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
3. 디플로이먼트(Deployment)
디플로이먼트는 레플리카셋의 상위 오브젝트이다. 때문에 디플로이먼트를 생성하면 레플리카셋, 파드가 자동 생성된다. 디플로이먼트는 애플리케이션에 대한 배포, 관리를 담당한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx
template:
metadata:
name: my-nginx-pod
labels:
app: my-nginx
spec:
containers:
- name: nginx
image: nginx:1.10
ports:
- containerPort: 80 # 파드 내에서 사용할 내부 포트, 외부에 노출되지 않는다.
디플로이먼트를 사용하면 레플리카셋 변경 사항을 저장하는 리비전(revision, 롤백에 사용), 무중단 배포가 가능하다.
4. 서비스(Service)
디플로이먼트로 배포된 애플리케이션은 외부에서 접근할 수 없다. 또 한, 파드 IP는 영속적이지 않기 때문에 여러 개의 디플로이먼트를 하나의 완벽한 애플리케이션으로 연동하기 위해서는 파드 IP가 아닌, 다른 방법을 사용해야 한다.
파드 내부에서 사용하는 포트를 외부에 노출하거나 다른 디플로이먼트의 파드들이 접근하게 하기 위해서는 서비스라는 오브젝트를 생성해야한다. 서비스는 파드에 접근하기 위한 규칙을 정의한다. 서비스 핵심 기능은 다음과 같다.
- 여러 개의 파드에 쉽게 접근할 수 있게 고유한 도메인 이름을 부여한다.
- 여러 개의 파드에 접근할 때, 요청을 분산하는 로드 밸런서 기능을 수행한다.
- 클라우드 플랫폼의 로드 밸런서, 클러스터 노드의 포트 등을 통해 파드를 외부로 노출한다.
서비스는 파드 접근 방식에 따라 여러 종류가 존재한다. 그 중, 주로 사용하는 서비스 타입은 다음과 같다.
- Cluster IP: 쿠버네티스 내부에서만 파드들에 접근할 때 사용한다. 외부로 파드를 노출하기 않는다.
- NodePort: 파드에 접근할 수 있는 포트를 클러스터의 모든 노드에 동일하게 개방한다. 외부에서 파드에 접근할 수 있게 한다. 기본적으로 랜덤한 포트를 사용하지만, 특정 포드로 접근하게 설정할 수 있다.
- LoadBalancer: 클라우드 플랫폼에서 제동하는 로드 밸런서를 동적으로 프로비저닝해 파드에 연결한다. 외부에서 파드에 접근할 수 있게 한다. 일반적으로 AWS 같은 클라우드 플랫폼에서만 지원한다.
아래 설명에서 설명할 서비스 설정에 사용하는 디플로이먼트는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
apiVersion: apps/v1
kind: Deployment
metadata:
name: hostname-deployment
spec:
replicas: 3
selector:
matchLabels:
app: webserver
template:
metadata:
name: my-webserver
labels:
app: webserver
spec:
containers:
- name: my-webserver
image: alicek106/rr-test:echo-hostname
ports:
- containerPort: 80
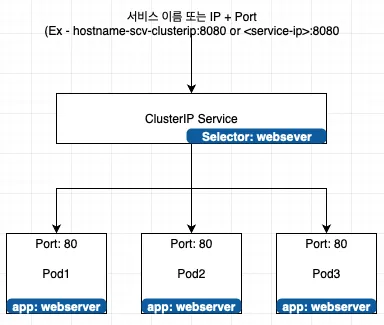
4.1 ClusterIP
ClusterIP 타입으로 서비스를 사용하는 방법은 다음과 같다
1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: v1
kind: Service
metadata:
name: hostname-svc-clusterip
spec:
ports:
- name: web-port
port: 8080 # 서비스의 IP에 접근할 수 있는 포트
targetPort: 80 # selector 항목에 의해 접근 대상이 된 파드들이 내부적으로 사용하는 포트
selector: # 해당 서비스에서 어떤 라벨을 가지는 파드에 접근할 수 있는지 결정
app: webserver # app: webserver라는 라벨을 가진 파드에 접근
type: ClusterIP # 서비스 타입
서비스는 생성될 때 별도의 설정을 하지 않아도 연결된 파드들에 대해 로드 밸런싱을 수행한다. 또 한, 내부 DNS를 제공하고 있어서 IP 뿐만 아니라 파드와 연결된 서비스 이름으로도 접근할 수 있다.
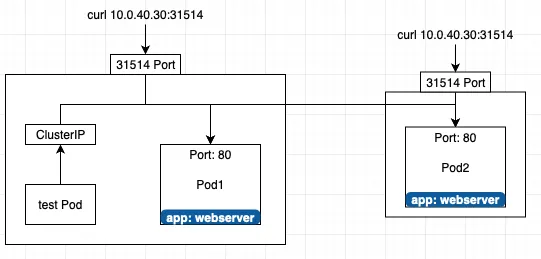
4.2 NodePort
NodePort는 모든 노드의 특정 포트를 외부에 개방한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion: v1
kind: Service
metadata:
name: hostname-svc-nodeport
spec:
ports:
- name: web-port
port: 8080
targetPort: 80
nodePort: 3000 # 내가 노출하고 싶은 포트 설정, 설정이 없다면 30000 ~ 32768 중 랜덤 선택
selector:
app: webserver
type: NodePort
NodePort는 ClusterIP 기능을 포함하고 있다. 때문에 NodePort에서는 자동으로 ClusterIP 기능을 사용할 수 있다.
 실제 운영에서 NodePort를 사용하는 경우는 많지 않다. SSL 인증서 적용, 라우팅 등 복잡한 설정을 적용하기 어렵기 때문이다. 때문에 NodePort 서비스 자체를 통해 서비스를 외부로 제공하기 보다는, 인그레스(Ingress)라는 오브젝트에서 간접적으로 사용되는 경우가 많다.
실제 운영에서 NodePort를 사용하는 경우는 많지 않다. SSL 인증서 적용, 라우팅 등 복잡한 설정을 적용하기 어렵기 때문이다. 때문에 NodePort 서비스 자체를 통해 서비스를 외부로 제공하기 보다는, 인그레스(Ingress)라는 오브젝트에서 간접적으로 사용되는 경우가 많다.
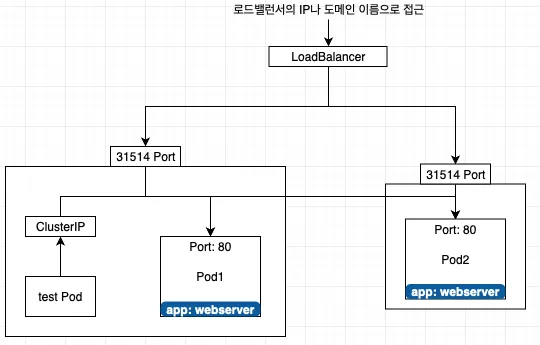
4.3 LoadBalancer
NodePort는 각 노드 IP를 알아야만 접근이 가능했다. LoadBalancer는 클라우드 플랫폼에서 부터 도메인 이름과 IP를 할당받기 때문에 NodePort보다 더 쉽게 파드에 접근할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
apiVersion: v1
kind: Service
metadata:
name: hostname-svc-lb
annotations:
# 쿠버네티스 1.8 기준
# 네트워크 로드밸런서 사용을 위한 설정, 없다면 AWS의 class load balancer를 기본으로 사용
service.beta.kubernetes.io/aws-load-balancer-type: "nlb"
spec:
ports:
- name: web-port
port: 80 # 로드 밸런서에 접근하기 위한 포트
targetPort: 80
selector:
app: webserver
type: LoadBalancer
LoadBalancer 타임은 서비스가 생성될 때 모든 워커 노드 파드에 접근할 수 있는 랜덤한 포트를 개발한다. 때문에 NodePort의 기능을 사용할 수 있다.
5. externalTrafficPolicy 속성 - 트래픽 분배를 결정하는 서비스 속성
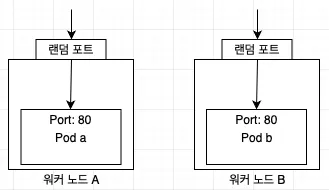
LoadBalancer 타입 서비스를 사용하면 외부로부터 온 요청은 노드 중 하나로 전송 → 노드에서 다시 파드 중 하나로 전송 된다. NodePort 타입은 각 노드로 들어온 요청이 파드 중 하나로 전송된다. 이런 방식은 때에 따라 효율적이지 않다. 아래와 같은 경우 워커 노드 A → 워커 노트 B의 파드 b로 리다이렉트가 발생한다. 불필요한 네트워크 홉이 하나 더 발생했고, 트래픽의 출발지 주소가 바뀌는 NAT가 발생했다.
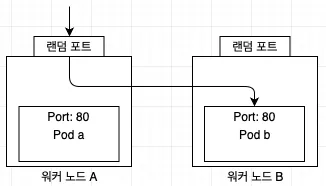 트래픽이 이렇게 분배되는 이유는 externalTrafficPolicy 설정 때문이다. 이 설정의 기본값은 Cluster이며 위 설명과 같이 동작한다. 만약 이 설정을 Local로 설정하면 파드가 생성된 노드에서만 파드로 접근할 수 있다. 때문에 네트워크 홉이 발생하지 않고, 전달되는 요청의 클라이언트 IP도 보존된다.
트래픽이 이렇게 분배되는 이유는 externalTrafficPolicy 설정 때문이다. 이 설정의 기본값은 Cluster이며 위 설명과 같이 동작한다. 만약 이 설정을 Local로 설정하면 파드가 생성된 노드에서만 파드로 접근할 수 있다. 때문에 네트워크 홉이 발생하지 않고, 전달되는 요청의 클라이언트 IP도 보존된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion: v1
kind: Service
metadata:
name: hostname-svc-lb-local
spec:
externalTrafficPolicy: Local
ports:
- name: web-port
port: 80
targetPort: 80
selector:
app: webserver
type: LoadBalancer
 Local 설정은 각 노드에 파드가 고르지 않게 스케줄링 되었을 때 요청이 제대로 분산되지 않아 자원 활용율이 떨어질 수 있다는 문제가 있다.
Local 설정은 각 노드에 파드가 고르지 않게 스케줄링 되었을 때 요청이 제대로 분산되지 않아 자원 활용율이 떨어질 수 있다는 문제가 있다.