1. 언어 AI란?
인공 지능 이론 창시자 중 한명인 존 매카시가 내린 정의는 다음과 같다.
- 인공 지능은 지능적인 기계, 특히 지능적인 컴퓨터 프로그램을 만드는 과학과 공학이다. 인공 지능 분야는 컴퓨터를 활용해 인간 지능이 어떻게 작동하는지를 이해하려고 연구한다. 하지만 AI가 생물학적으로 관찰되는 방법에만 국한되지는 않는다.
언어 AI(Language AI)는 인간 언어를 이해, 처리, 생성할 수 있는 기술에 초첨을 맞춘 AI의 하위 분야이다.
2. 언어 AI의 최근 역사
컴퓨터는 언어를 이해하기에 최적화되어 있지 않다. 텍스트는 비구조적이라 0과 1로 변환되면 의미를 잃기 때문이다. 때문에 언어 AI는 언어를 구조적으로 바꾸는 방식에 초점을 맞추어 발전했다. 여기서 비구조적의 의미는 정형 데이터가 아니라는 의미이다(사전에 정의된 형식, 모델을 따르지 않는다.). 언어가 비구조적인 이유는 형식이 자유롭고, 의미 경계가 모호하며, 데이터 저장 관점에서 정해진 규칙이 없기 때문이다.
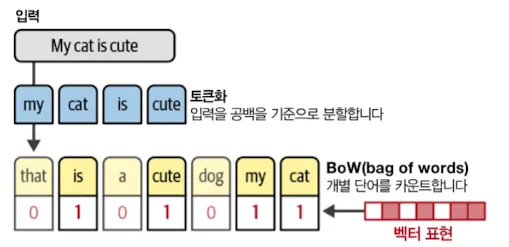
2.1 BoW(Bag of Words)로 언어 표현하기
Bow의 작동 방식은 다음과 같다.
- 단어를 토큰화한다.
- 토큰화된 고유 단어를 합쳐서 어휘사전을 만든다.
- 어휘사전에서 각 문장에 단어가 얼마나 많이 등장하는지를 확인한다.
1
2
3
-- 용어 정리
1. LLM에서 벡터는 텍스트가 숫자로 변환된 배열이다. 컴퓨터는 이 숫자들을 이용해 의미를 파악한다.
LLM은 벡터를 학습할 때 의미적으로 유사한 단어들은 벡터 공간에서 서로 가까운 위치에 놓이게 학습한다.
2.2 밀집된 벡터 임베딩으로 더 나은 표현 만들기
BoW방식은 텍스트 의미(문맥)을 무시하고 단어의 모음 정도로만 생각하는 문제가 있다. word2vec 임베딩은 텍스트 의미를 파악하는데 성공한 첫 시도다. 임베딩은 데이터 의미를 포착하기 위한 벡터 표현이다. 임베딩의 값은 단어를 표현하는 데 사용할 수 있는 속성이다. 이 벡터를 표현하기 위해 신경망으로 방대한 양의 텍스트를 훈련해 단어의 의미를 찾아낸다.
- 임베딩의 핵심은 의미의 유사성을 유지하면서 고차원 데이터를 저차원 데이터로 매핑하는 것이다.
- 임베딩 종류는 다양하다(단어 수준 추상화, 문장 수준 추상화…)
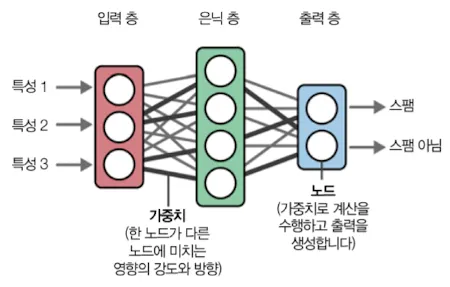
신경망은 노드와 가중치(파라미터)로 이루어져있다.
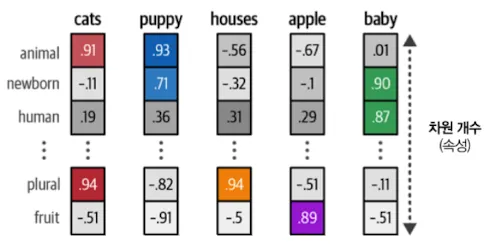
 word2vec은 문장에서 다음에 등장하는 단어를 이용해 단어 임베딩을 생성한다. 개략적인 과정은 다음과 같다
word2vec은 문장에서 다음에 등장하는 단어를 이용해 단어 임베딩을 생성한다. 개략적인 과정은 다음과 같다
- 어휘 사전에 있는 모든 단어에 랜덤한 값을 할당한다.
- 훈련 스텝마다 데이터에 있는 단어쌍을 가져와서 단어들이 문장 안에서 이웃할 가능성을 판단한다.
- 이 과정을 통해 단어의 의미의 유사성을 포착한다.
2.3 어텐션을 사용한 문맥 인코딩과 디코딩
- 하나의 단어 의미는 문맥에 따라 달라진다. 임베딩은 문맥에 따라 달라져야하는데, 이는 RNN(Recurrent Neural Network)를 이용하면된다.
- RNN은 두 가지 작업을 한다.
- 인코딩: 인코더를 이용해 입력 문장을 표현한다..
- 디코딩: 디코더를 이용해 출력 문장을 생성한다.
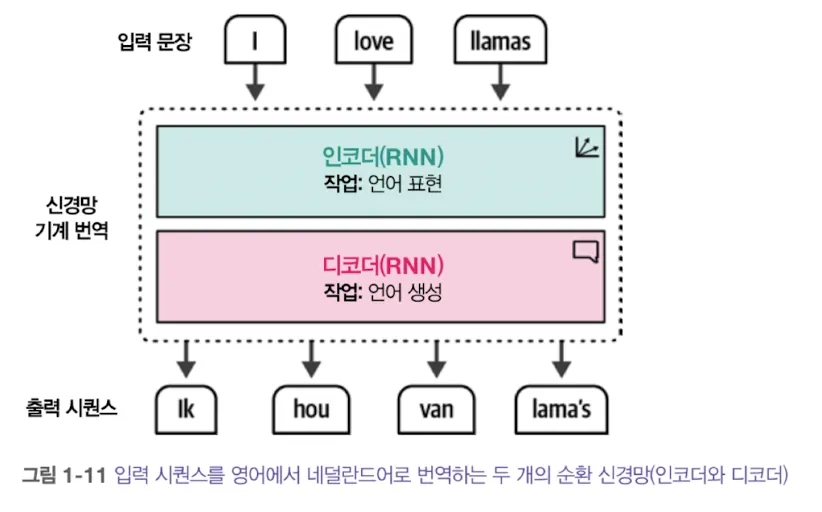
- RNN은 각 단계가 자기회귀적(auto regressive)인데 이는 과거 출력과 상태가 현재와 미래 출력에 영향을 주기 때문이다.
 이 과정이 반복될 수록 초반에 나왔던 단어정보가 희미해지는 문제가 발생했고 이를 해결한 것이 어텐션(attention)이다. 어텐션은 과거 정보를 누적하는 대신, 단어와 단어 사이 연관성에 집중해서 관련이 높은 단어 간 가중치를 높게 준다.
이 과정이 반복될 수록 초반에 나왔던 단어정보가 희미해지는 문제가 발생했고 이를 해결한 것이 어텐션(attention)이다. 어텐션은 과거 정보를 누적하는 대신, 단어와 단어 사이 연관성에 집중해서 관련이 높은 단어 간 가중치를 높게 준다.
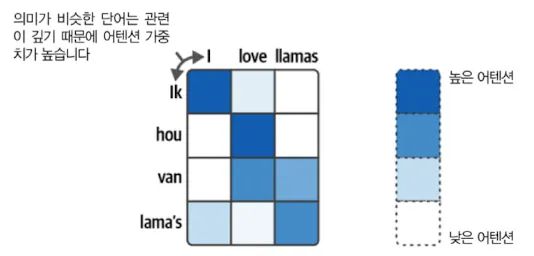
- 어텐션을 RNN 과정에 사용하면 결과 출력 전에 어텐션을 이용해서 연관이 깊은 단어를 출력한다. 하지만, RNN은 결과 출력을 위해 이전 결과가 필요하다는 구조적 문제를 가지고 있어서 모델 훈련을 병렬화하기 어렵다.
2.4 Attention Is All You Need
- LLM 분야는
라는 논문 출간 이후 큰 발전을 이루었다. 이 논문에서는 학습 부분에서 자기 회귀적인 매커니즘을 빼고 어텐션 메커니즘만 사용하는 신경망 구조를 제안했다. 덕분에 병렬 학습이 가능해져서 훈련 속도를 크게 높였다. 다만, 추론 과정은 여전히 자기 회귀적이다. 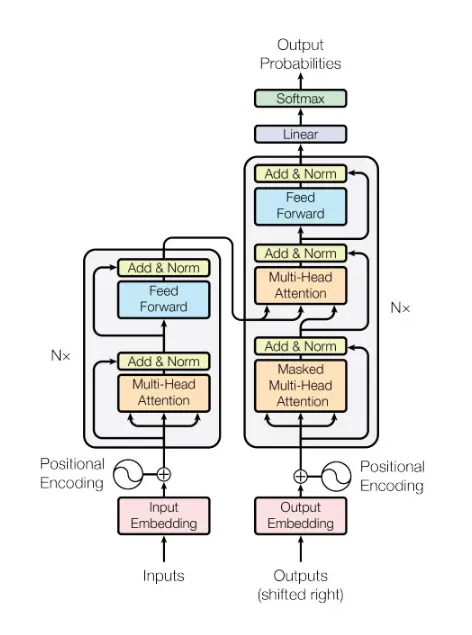 - 트랜스포머 인코더는 셀프 어텐션(Self-Attention)과 피드포워드 신경망(feedforward neural network)으로 구성된다.
- 셀프 어텐션은 단어 사이 관계와 맥락 파악에 집중한다
- 피드포워드 신경망은 단어 간의 연관성 대신 각 위치에 있는 단어 하나에 독립적으로 동일한 계산을 적용한다. 이를 통해 각 단어가 가진 특징을 더 정교하게 다듬는다.
- 디코더는 masked attention, encoder attention, feed forward으로 이루어진다.
- masked attention은 디코더가 단어를 하나씩 생성할 수 있게, 아직 생성되지 않은 미래 단어를 보지 못하게 마스킹하는 역할을 한다.
- 이는 학습 과정에서 답을 커닝하지 못하게 하는 역할을 한다.
- 학습은 이미 정답을 가지고 진행한다. 이 때, 트랜스포머는 속도를 높이기 위해 정답 문장 전체를 디코더에 입력한다.
- 때문에, 별도로 정답 문장을 마스킹하지 않으면 답을 미리 인지하게 된다.
- 여기서 마스킹이란 Attention score를 0으로 만드는 것을 의미한다.
- encoder attention(multi-head attention)은 인코더가 분석한 입력 문장 정보 중 지금 단어를 만들 때 어떤 부분에 집중해야할지를 결정한다.
- feed forward: 정보를 고도화하고 학습을 돕는다.
- masked attention은 디코더가 단어를 하나씩 생성할 수 있게, 아직 생성되지 않은 미래 단어를 보지 못하게 마스킹하는 역할을 한다.