- RAG는 출력을 개선하기 위한 다양한 방법이 고안되어 있다.
- Langchain이 공개한 rag-from-scratch 레포지터리에서는 다음과 같은 방법들이 소개되고 있다.
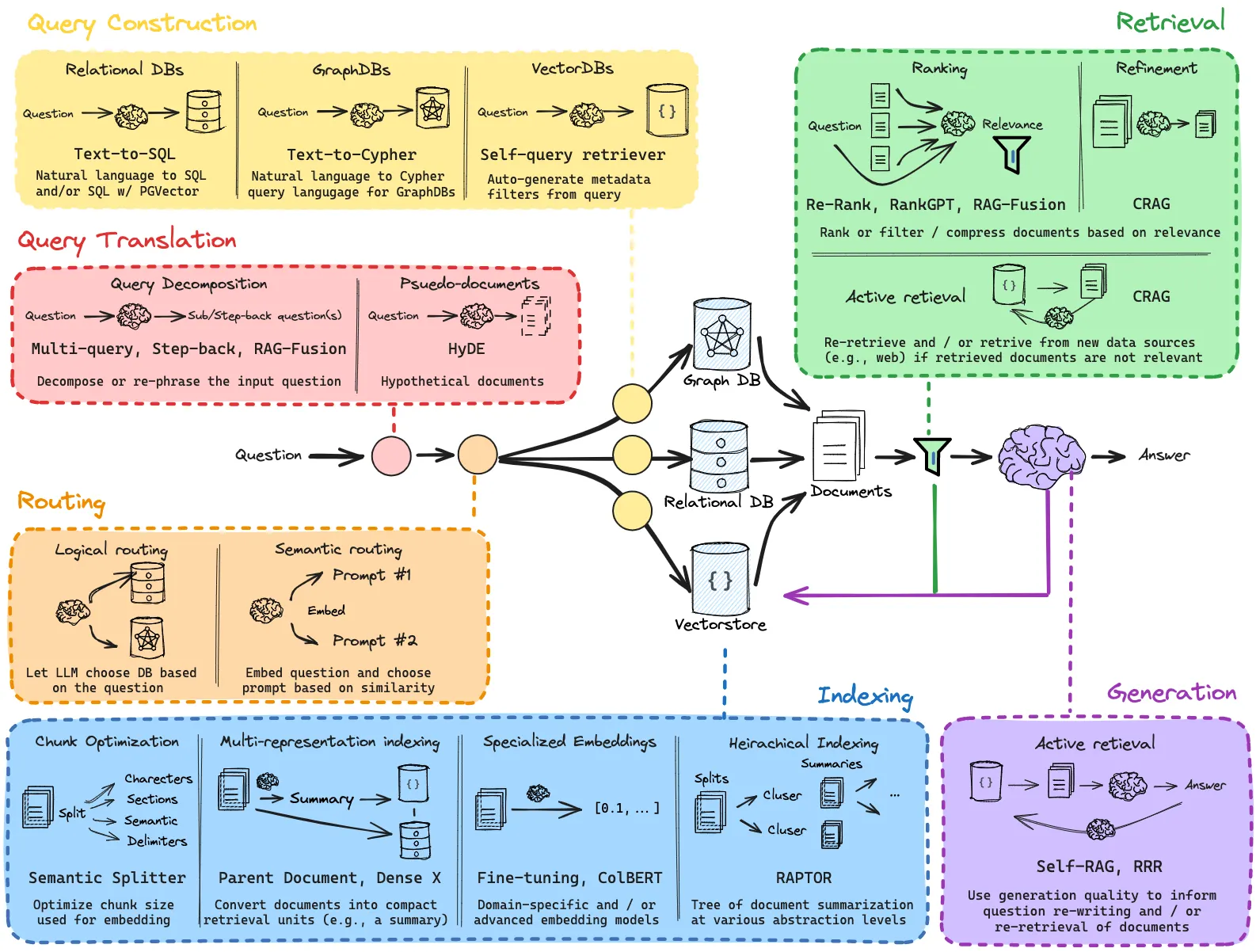
- 이 중 검색 쿼리 기법, 검색 후 기법, 복수 Retriever를 사용하는 기법을 살펴보자.
1. 실습 준비
1
pip install langchain-core langchain-openai langchain-community GitPython langchain-chroma tavily-python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
import os
from dotenv import load_dotenv
from langchain_community.document_loaders import GitLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain.libs.core.langchain_core.runnables.passthrough import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_chroma import Chroma
load_dotenv()
OPEN_API_KEY = os.environ.get("OPEN_API_KEY")
REPO_URL = "https://github.com/langchain-ai/langchain"
LOCAL_PATH = "./langchain"
BRANCH = "master"
loader = GitLoader(
clone_url=REPO_URL,
repo_path=LOCAL_PATH,
branch=BRANCH,
# 특정 폴더(docs) 내의 마크다운 파일만 가져오도록 필터링
file_filter=lambda file_path: (file_path.endswith(".md"))
)
data = loader.load()
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
api_key=OPEN_API_KEY,
)
db = Chroma.from_documents(data, embeddings)
prompt = ChatPromptTemplate.from_template('''
Please answer the question by considering only the following context.
context: """
{context}
"""
question: {question}
''')
model = ChatOpenAI(model="gpt-4o-mini", temperature=0, api_key=OPEN_API_KEY)
retriever = db.as_retriever()
chain = {
"question": RunnablePassthrough(),
"context": retriever,
} | prompt | model | StrOutputParser()
chain.invoke("Tell me the introduction of LangChain")
2. 검색 쿼리 기법
- 단순한 RAG 에서는 질문과 유사한 문서를 검색하지만, 실제로 필요한 것은 답변과 유사한 문서다.
- HyDE(Hypothetical Document Embeddings) 기법은 사용자 질문에 대해 LLM이 가상 답변을 추론하고 이를 벡터 유사도 검색에 사용한다.
- LLM이 가상 답변을 추론하기 쉬운 경우에 유용하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
hypothetical_prompt = ChatPromptTemplate.from_template("""
Answer the next question in one sentence
question: {question}
""")
hypothetical_chain = hypothetical_prompt | model | StrOutputParser()
hyde_rag_chain = {
"question": RunnablePassthrough(),
# 가상 답변을 생성하는 Chain 출력을 retriever에 전달
# retriever는 list[Docuemnt]를 전달
"context": hypothetical_chain | retriever,
} | prompt | model | StrOutputParser()
chain.invoke("Tell me the introduction of LangChain")
2.1 복수 검색 쿼리 생성
- LLM이 여러 검색 쿼리를 생성하게한다. 검색 쿼리가 많아지면 적절한 문서가 검색 결과에 포함될 가능성이 높아진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from pydantic import BaseModel, Field
class QueryGenerationOutput(BaseModel):
queries: list[str] = Field(..., description="query list")
query_generation_prompt = ChatPromptTemplate.from_template("""
Generate three different retrieval queries to fetch relevant documents from the vector database for the question. The goal is to provide multiple perspectives on the user’s query to overcome the limitations of distance-based similarity search
question: {question}
""")
# 검색 쿼리 문자열 리스트 출력
query_generation_chain = (
query_generation_prompt
| model.with_structured_output(QueryGenerationOutput)
| (lambda x: x.queries)
)
multi_query_rag_chain = {
"question": RunnablePassthrough(),
# retriever.map()은 list[list[Docuemnt]]를 반환
"context": query_generation_chain | retriever.map(),
} | prompt | model | StrOutputParser()
multi_query_rag_chain.invoke("Tell me the introduction of LangChain")
3. 검색 후 기법
- 검색 결과를 어떻게 정렬할지에 대한 소개이다.
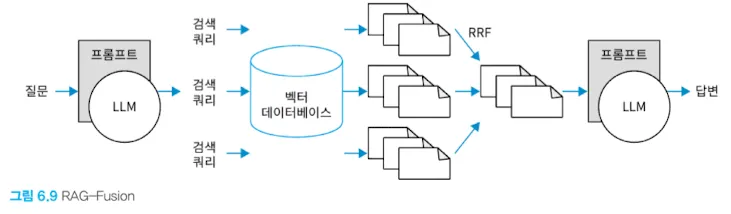
3.1 RAG-Fusion
- 각 쿼리 검색 결과를 프롬프트에 넣을 때 정렬 기준을 정해서 넣어야 한다.
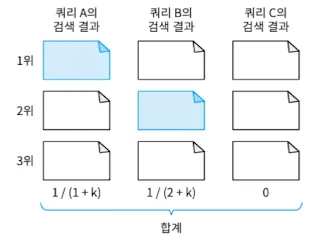
- RRF(Reciprocal Rank Fusion)는 각 검색 쿼리에서 나온 1 / (문서 순위 + k)의 합계를 점수로 해서 점수의 크기로 검색 결과를 정련한 것이다.
-
여러 검색 쿼리를 생성해서 검색 결과를 RRF로 정렬하는 RAG-Fusion을 도식화하면 다음과 같다.
 ```python
def reciprocal_rank_fusion(
retriever_outputs: list[list[Document]],
k: int = 60,
) -> list[str]:
# 각 문서의 콘텐츠와 그 점수의 매핑을 저장하는 딕셔너리 준비
content_score_mapping = {}
```python
def reciprocal_rank_fusion(
retriever_outputs: list[list[Document]],
k: int = 60,
) -> list[str]:
# 각 문서의 콘텐츠와 그 점수의 매핑을 저장하는 딕셔너리 준비
content_score_mapping = {}# 검색 쿼리마다 반복 for docs in retriever_outputs: for rank, doc in enumerate(docs): content = doc.page_content # 처음 등장한 콘텐츠인 경우 점수를 0으로 초기화 if content not in content_score_mapping: content_score_mapping[content] = 0
1 2
#(1 / (순위 + k)) 점수를 추가 content_score_mapping[content] += 1 / (rank + k)ranked = sorted(content_score_mapping.items(), key=lambda x : x[1], reverse=True)
return [content for content, _ in ranked]
rag_fusion_chain = { “question”: RunnablePassthrough(), “context”: query_generation_chain | retriever.map() | reciprocal_rank_fusion, } | prompt | model | StrOutputParser()
rag_fusion_chain.invoke(“Tell me the introduction of LangChain”)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
## 3.2 리랭크 모델 개요
- 때로는 하나의 검색 결과 순위를 다시 정렬(re-rank)하는 것이 도움이 되는 경우가 있다.
- RRF의 경우 질문과 문서가 얼마나 유사한지만 체크하기 때문에 미묘한 논리적 관계까지 파악하지 못한다. 리랭크의 경우 질문과 문서를 하나의 쌍으로 LLM에 넣기 때문에 진짜 필요한 답인지를 판단할 수 있다. 하지만 계산 비용이 높은 문제가 있다.
- 계산 비용 문제 해결을 위해 우선 비용이 낮은 임베딩 벡터의 유사도 검색을 진행 후 리랭크 모델을 적용하기도 한다.
- [cohere](https://dashboard.cohere.com/) API를 이용해 리랭크를 진행하는 예시는 다음과 같다
```python
def rerank(inp: dict[str, Any], top_n: int = 3) -> list[Document]:
question = inp["question"]
documents = inp["documents"]
cohere_reranker = CohereRerank(model="rerank-multilingual-v3.0", top_n=top_n)
return cohere_reranker.compress_documents(
documents = documents,
query=question,
)
rerank_rag_chain = (
{
"question": RunnablePassthrough(),
"documents": retriever
}
| RunnablePassthrough.assign(context=rerank)
| prompt | model | StrOutputParser()
)
rerank_rag_chain.invoke("Tell me the introduction of LangChain")
4. 복수 Retriever를 활용하는 기법
- 상황에 맞은 여러 Retriver를 사용할 수 있다.
4.1 LLM에 의한 라우팅
- 사용자 질문에 따라 검색 대상 Retirever를 구분해 사용할 수 있다.
- LangChain 공식 문서와 웹 검색을 구분 해 사용하는 RAG 구성 예시는 다음과 같다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
from langchain_community.retrievers import TavilySearchAPIRetriever
from enum import Enum
langchain_document_retriever = retriever.with_config({
"run_name": "langchain_document_retriever",
})
web_retriever = TavilySearchAPIRetriever(k=3).with_config({
"run_name": "web_retriever",
})
class Route(str, Enum):
langchain_document = "langchain_document"
web = "web"
class RouteOutput(BaseModel):
route: Route
route_prompt = ChatPromptTemplate.from_template("""
Select suitable Retriever for answering the question
question: {question}
""")
route_chain = (
route_prompt
| model.with_structured_output(RouteOutput)
| (lambda x: x.route)
)
def routed_retriever(inp: dict[str, Any]) -> list[Document]:
question = inp["question"]
route = inp["route"]
if route == Route.langchain_document:
return langchain_document_retriever.invoke(question)
elif route == Route.web:
return web_retriever.invoke(question)
raise ValueError(f"Unknown Retriever: {route}")
route_rag_chain = ({
"question": RunnablePassthrough(),
"route": route_chain,
}
| RunnablePassthrough.assign(context=routed_retriever)
| prompt | model | StrOutputParser())
route_rag_chain.invoke("Tell me the introduction of LangChain")
4.2 하이브리드 검색 예시
- 여러 Retirever의 검색 결과(여러 검색 기법)를 조합해 사용하는 것을 하이브리드 검색이라 한다.
- 하이브리드 검색 예시로 Embedding 모델과 TF-IDF 또는 BM25(TF-IDF의 확장 형태, Ealsticsearch 기본 알고리즘)를 같이 사용하는 것이 있다.
- Embedding 모델은 학습 데이터 범위 내에서 의미가 유사한 텍스트의 벡터 유사도가 높다.
- 다만, 범용 Embedding 모델에서 전문 용어 유사도 검색이 어렵다.
- 임베딩 모델은 벡터의 모든 수치가 0이 아니여서 밀집 벡터(Dense Vector)라고 한다.
- TF-IDF, BM25는 단어 등장 빈도 기반으로 텍스트 유사도를 검색한다.
- 공통 단어가 많은 텍스트에 대해 벡터 유사도가 높아져서 고유명사, 전문용어 유사도 검색에 효과적이다.
- 단어 목록에 대해 등장 횟수를 보기 때문에 벡터의 많은 요소가 0이 된다. 때문에 회소 벡터(Spare Vector)라고 한다.
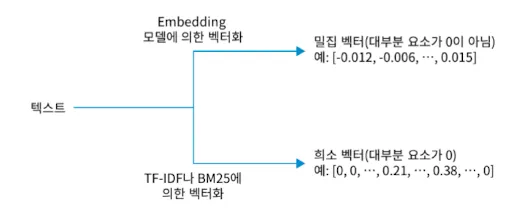
- Embedding 모델은 학습 데이터 범위 내에서 의미가 유사한 텍스트의 벡터 유사도가 높다.
4.2.1 하이브리드 검색 구현
- 위에서 설명한 BM25, LangChain 공식 문서에 대한 임베딩 벡터의 유사도 검색을 사용한 검색 조합 예시를 보자. 검색 결과 순위 융합에는 위에서 설명했던 RRF를 사용한다.
1
pip install rank-bm25
```python from langchain_community.retrievers import BM25Retriever from langchain_core.runnables import RunnableParallel
chroma_retriever = retriever.with_config({ “run_name”: “chroma_retriever”, }) bm25_retriever = BM25Retriever.from_documents(data).with_config({ “run_name”: “bm25_retriever”, })
hybrid_retriever = ( RunnableParallel({ “chroma_documents”: chroma_retriever, “bm25_documents”: bm25_retriever, }) | (lambda x: [x[“chroma_documents”], x[“bm25_documents”]]) | reciprocal_rank_fusion )
hybrid_rag_chain = ({ “question”: RunnablePassthrough(), “context”: hybrid_retriever, } | prompt | model | StrOutputParser())
hybrid_rag_chain.invoke(“Tell me the introduction of LangChain”) ```